こんにちは!オルターブースのいけだです。
気づけば、もう2月ですね。今年もあっという間の1年になりそうな気がしています😅
さて、今回はAzure AI SearchのAzure OpenAI Embedding スキルを使い、Cosmos DBとの統合をおこなってみようと思います。
目次
AI Searchとは
Azure AI Search (旧称 "Azure Cognitive Search") は、従来の会話型検索アプリケーションのユーザー所有コンテンツに対して、安全な情報取得を大規模に提供する、AzureのAIを利用した情報取得プラットフォームです。 Azure AI Searchは、ベクター検索、全文検索、ハイブリッド検索、あいまい検索、オートコンプリート、Geo検索などの豊富な機能を備えています。
直近ではAzure OpenAI Serviceと組み合わせることで、検索した資料を基にした回答ができるチャットボットの作成にも活用されています。
沢山の機能があるAI Searchですが、今回は機能の1つである、「組み込みスキル」の Azure OpenAI Embedding スキルを使用してみます。
この機能は、Azure OpenAI Serviceにデプロイされている埋め込みモデルに接続して、スキルセットの実行中に埋め込みを生成します。
2023-10-01-Preview REST API、Azure portal、およびこの機能を使用するように更新されたすべてのAzure SDK ベータパッケージを通じて利用できます。
これまではベクトル検索をおこなう為に、Azure OpenAI ServiceのAPIを使用するコードを記述し、検索したい対象のフィールドに対して埋め込みを行い、また検索クエリに対しても埋め込みをおこなう工程が必要でした。
もちろん、LangChainのようなライブラリを用いる事で抽象化され、簡単にその工程をおこなう事もできましたが、これをAzureのネイティブな機能に任せる事ができるようなった。という点はかなり魅力的に思います。
なお、この機能は現時点ではパブリックプレビュー段階ですので、ご注意ください。
前提条件
- Azure Cosmos DBがプロビジョニングされ、なんらかのデータが格納されている事。
- Azure OpenAI Serviceで
text-embedding-ada-002がデプロイされている事。
インデックスの作成
① Cosmos DBに以下のようにデータが格納されている状態です。今回使用したデータはこちらの公開データセットを用いました。
②「統合」セクションから「Azure Cognitive Search (現AI Search) の追加」を選択します。
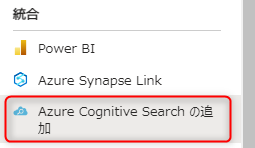
③ AI Search (旧Cognitive Search) リソースをデプロイします。
価格レベルですが、セマンティックランカーを使用しないようであれば、Freeレベルで試す事ができます。
④ インデックスを作成する
● データベース名、コレクション名をプルダウンで選択して次へ。
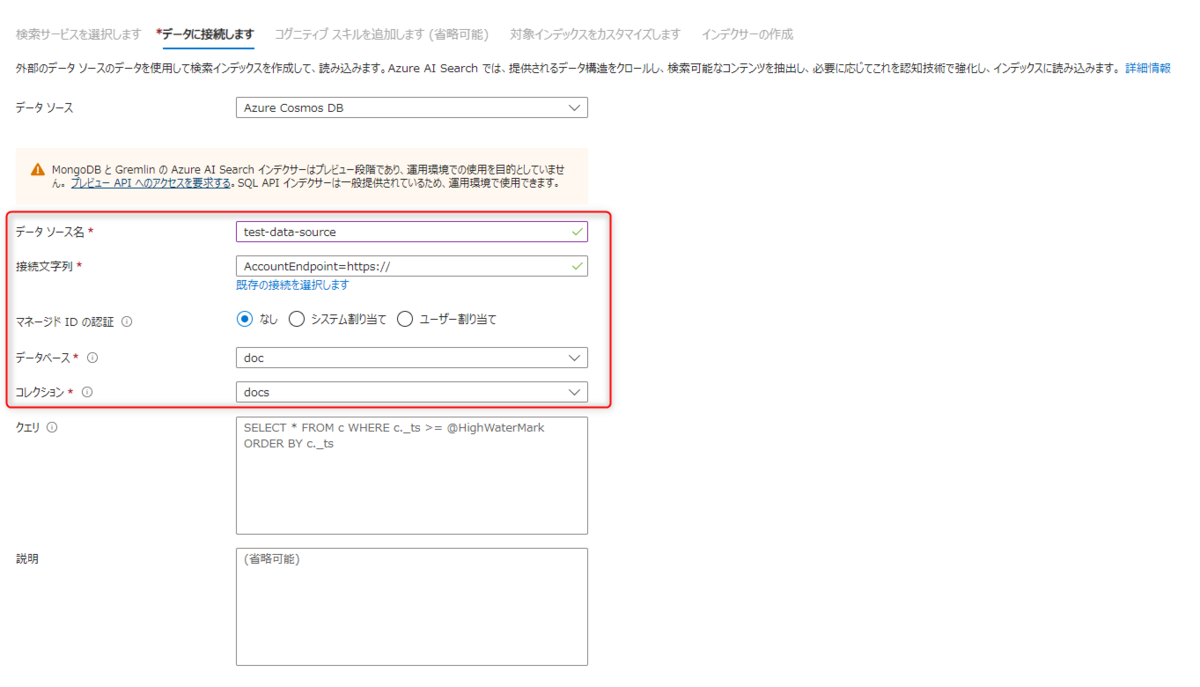
「コグニティブスキルを追加します」はスキップし「対象インデックスをカスタマイズ」へ。
● 各、フィールドに対して検索設定をおこないます。
- 取得可能 : 検索クエリで取得するかどうか。
- フィルター可能: フィルター検索の対象にするかどうか。
- ソート可能: 検索の際にソートを可能にするかどうか。
- 検索可能: 全文検索の対象にするかどうか。
- アナライザー: 検索時の言語指定。
● ベクトル用のフィールドを追加します。
- フィールド名:
embedding - 型:
Collection(Edm.Single)
→ 「・・・」から「ベクターフィールドの構成」をクリック。
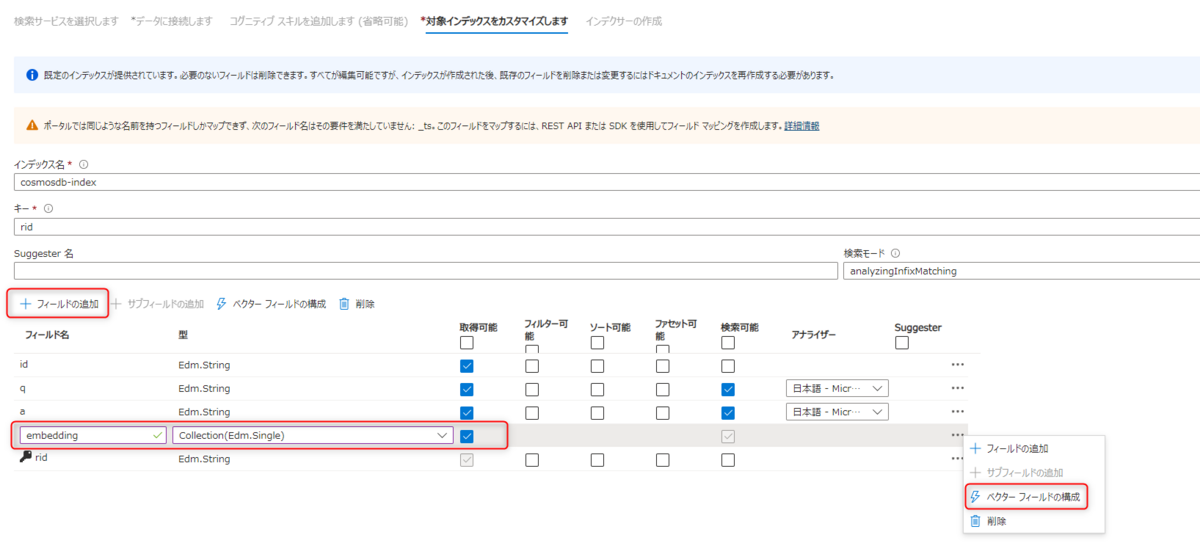
ベクターフィールドの構成では「ディメンション」を1536に。(text-embedding-ada-002 で埋め込みした際の次元数)
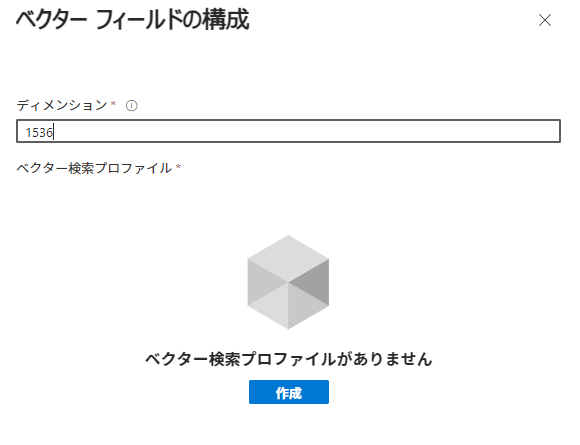
次に、ベクター検索プロファイルを作成します。

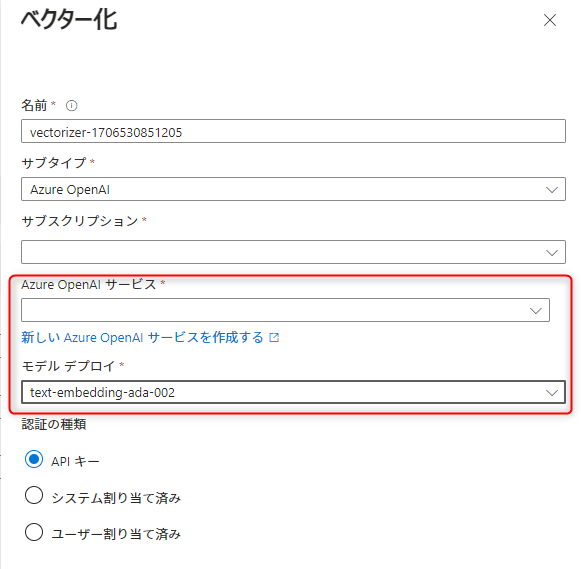
作成済みのAzure OpenAI Serviceとデプロイしている埋め込みモデル (text-embedding-ada-002)を選択します。
これでベクタープロファイルが作成できました。
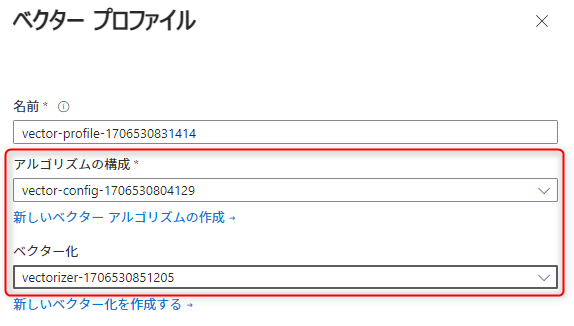
次に「インデクサーの作成」へ進みます。
インデクサーとは?
機能の説明 - Azure AI Search | Microsoft Learn
インデクサーは、プライマリ データ ストア内の検索可能なコンテンツを抽出するために、サポートされているデータ ソースからのデータ インポートを自動化する機能です。 インデクサーによって JSON のシリアル化は自動的に処理されます。 また、ほとんどの場合、何らかの形の変更と削除の検出がサポートされます。 Azure SQL Database、Azure Cosmos DB、Azure BLOB ストレージを含むさまざまなデータ ソースに接続できます。
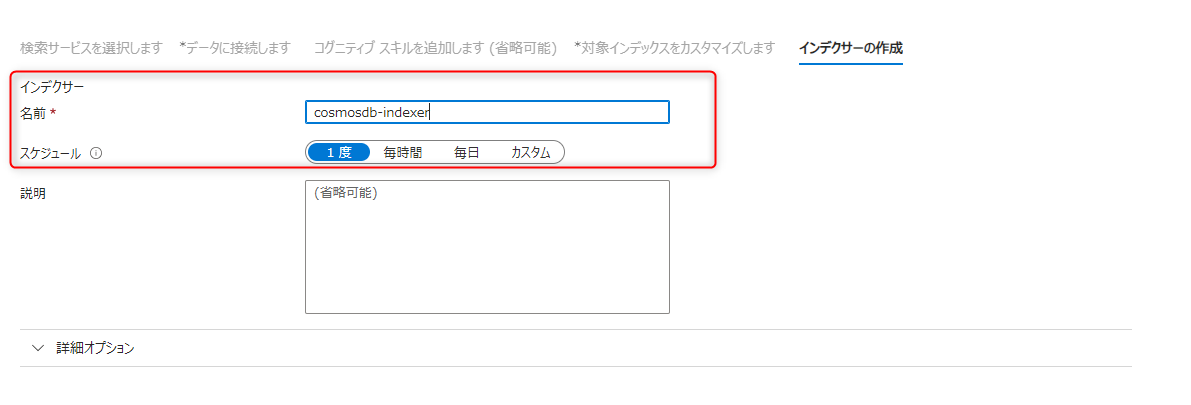
スケジュールで、インデクサーの実行をスケジュール化する事ができます。
ここまで終わったら「送信」をクリックします。
ポータル画面から作成した「Azure AI Search」リソースへ移動します。
インデックスが作成されている事が確認できます。
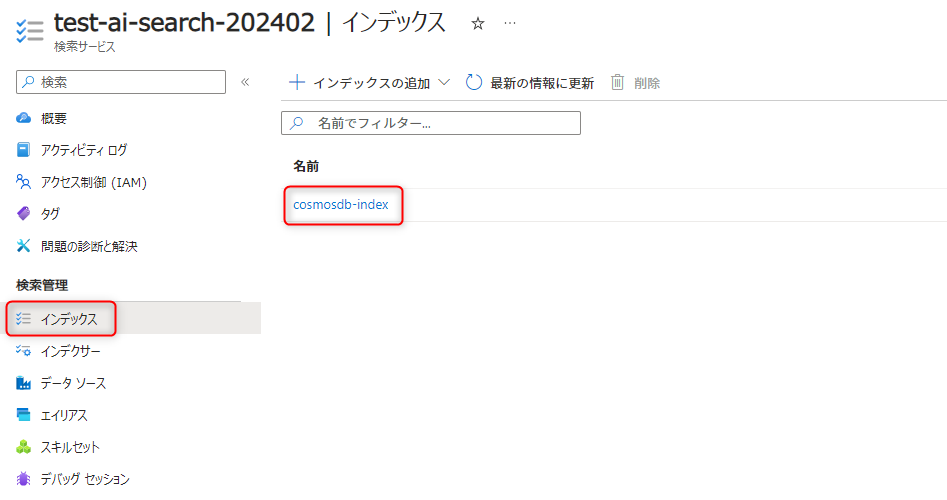
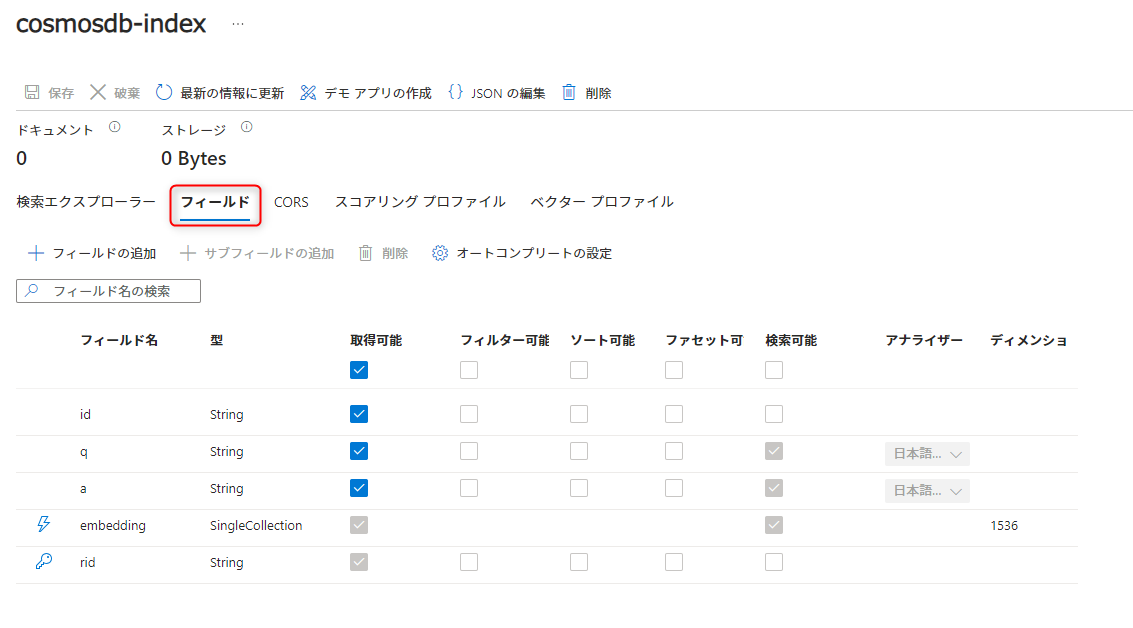
検索フィールドも確認できます。
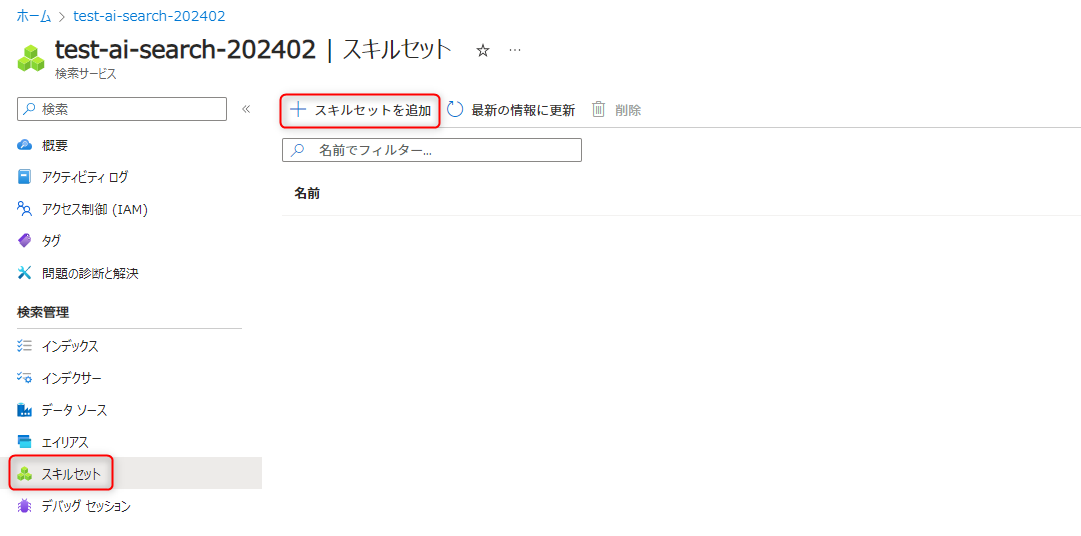
スキルセットの作成
次にAzure OpenAI Serviceにデプロイしているtext-embedding-ada-002を使い、自動的に埋め込みをおこなうための定義を設定します。
「スキルセットを追加」からスキルセットを作成します。
「スキル定義テンプレート」から「Azure OpenAI埋め込みスキル」を選択すると、テンプレートが表示されるのでコピーします。
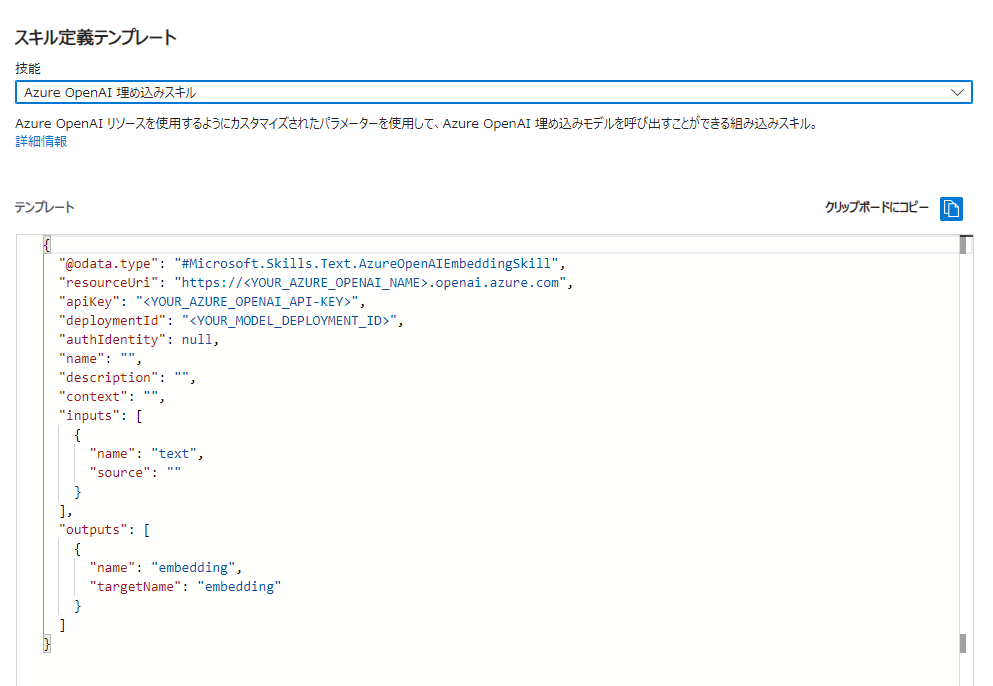
「スキルセットの定義(JSON)」の skills セクションにコピーしたテンプレートを貼り付けて、必要項目を修正します。
修正後は以下の形になりました。
{ "name": "test-skill", "description": "test", "skills": [ { "@odata.type": "#Microsoft.Skills.Text.AzureOpenAIEmbeddingSkill", "resourceUri": "<Azure OpenAI Endpoint>", "apiKey": "<Azure OpenAI API-KEY>", "deploymentId": "<DeployMentName>", "authIdentity": null, "name": "#1", "description": "", "context": "/document", "inputs": [ { "name": "text", "source": "/document/q" } ], "outputs": [ { "name": "embedding", "targetName": "embedding" } ] } ], "cognitiveServices": { "@odata.type": "#Microsoft.Azure.Search.DefaultCognitiveServices" } }
context:
documentこれはCosmos DBの各ドキュメントを表します。Azure Cognitive Searchのインデクサーは、データソースとして指定されたCosmos DBのコレクション内のドキュメントを処理します。inputs: 入力設定では、スキルセットが処理するデータのソースを指定しています。ここでは、
nameがtextと指定され、そのソースが/document/qであることを示しています。これは、処理対象のdocumentのqフィールドの内容を、textという名前でスキルに渡すことを意味しています。outputs: 出力設定では、スキルセットによる処理結果の出力方法を指定しています。ここでは、出力の
nameがembeddingであり、その処理結果をインデックスのtargetNameで指定されたembeddingフィールドに格納することを示しています。
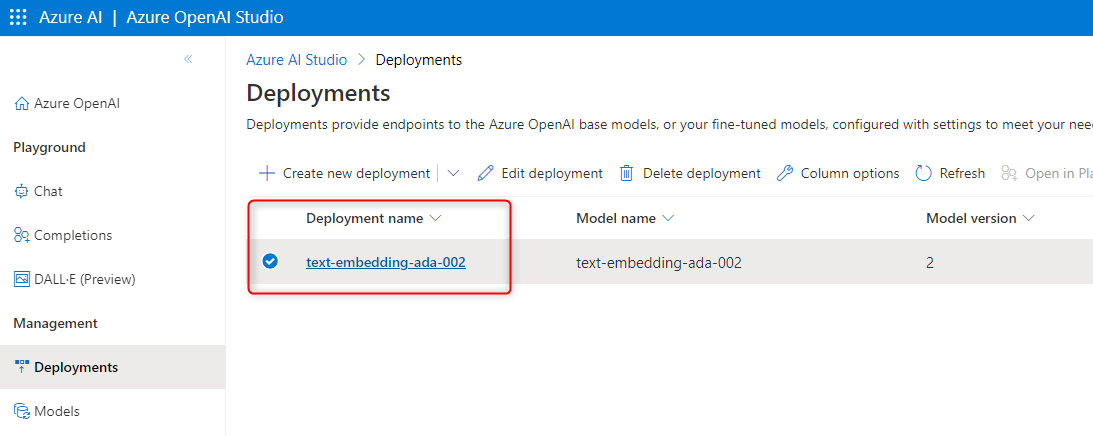
因みにAzure OpenAIのエンドポイントとAPIキーは「AzureOpenAI」リソースから確認可能です。

"DeployMentName"は「モデルデプロイ」>「 Azure AI Studio」> 「Deployments」から確認できます。
● 続いてインデクサー定義を修正します。
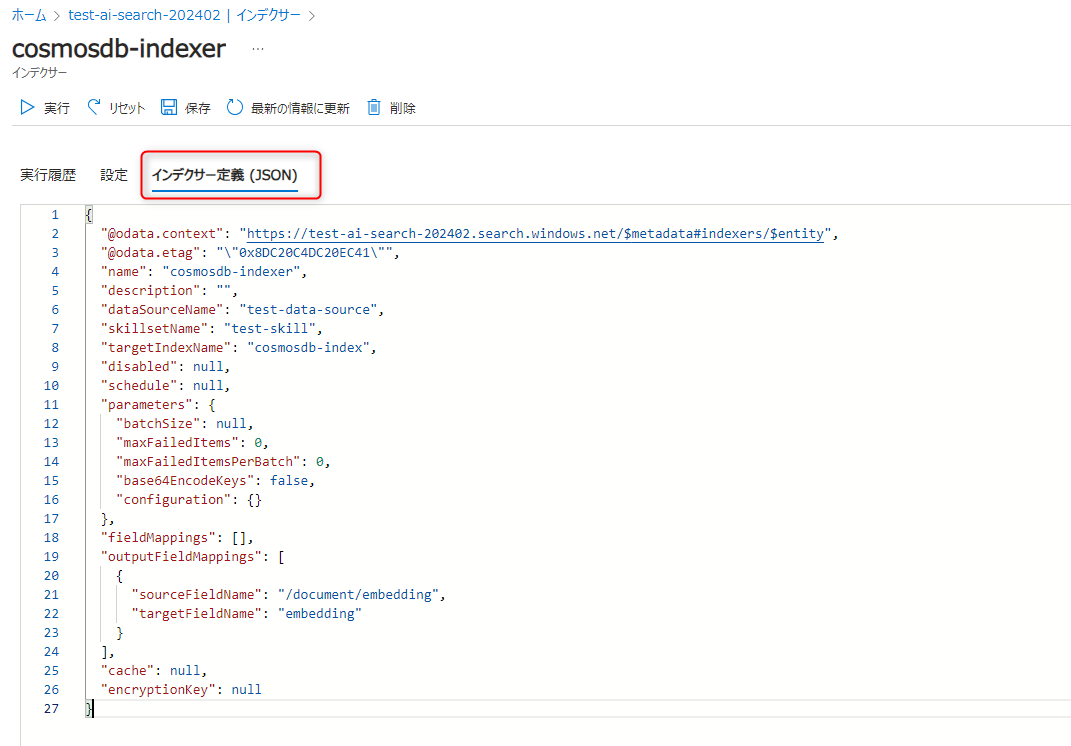
インデクサー定義の修正後は以下の形になりました。
{ "@odata.context": "https://test-ai-search-202402.search.windows.net/$metadata#indexers/$entity", "@odata.etag": "\"0x8DC20C4DC20EC41\"", "name": "cosmosdb-indexer", "description": "", "dataSourceName": "test-data-source", "skillsetName": "<作成したスキルセット名>", "targetIndexName": "cosmosdb-index", "disabled": null, "schedule": null, "parameters": { "batchSize": null, "maxFailedItems": 0, "maxFailedItemsPerBatch": 0, "base64EncodeKeys": false, "configuration": {} }, "fieldMappings": [], "outputFieldMappings": [ + { + "sourceFieldName": "/document/embedding", + "targetFieldName": "embedding" + } ], "cache": null, "encryptionKey": null }
修正できたら、「保存」→「リセット」→「実行」をします。 少し待つと、成功している事が確認できます。

試しにポータル画面から検索をしてみます。「インデックス」の「検索エクスプローラー」から検索する事ができます。
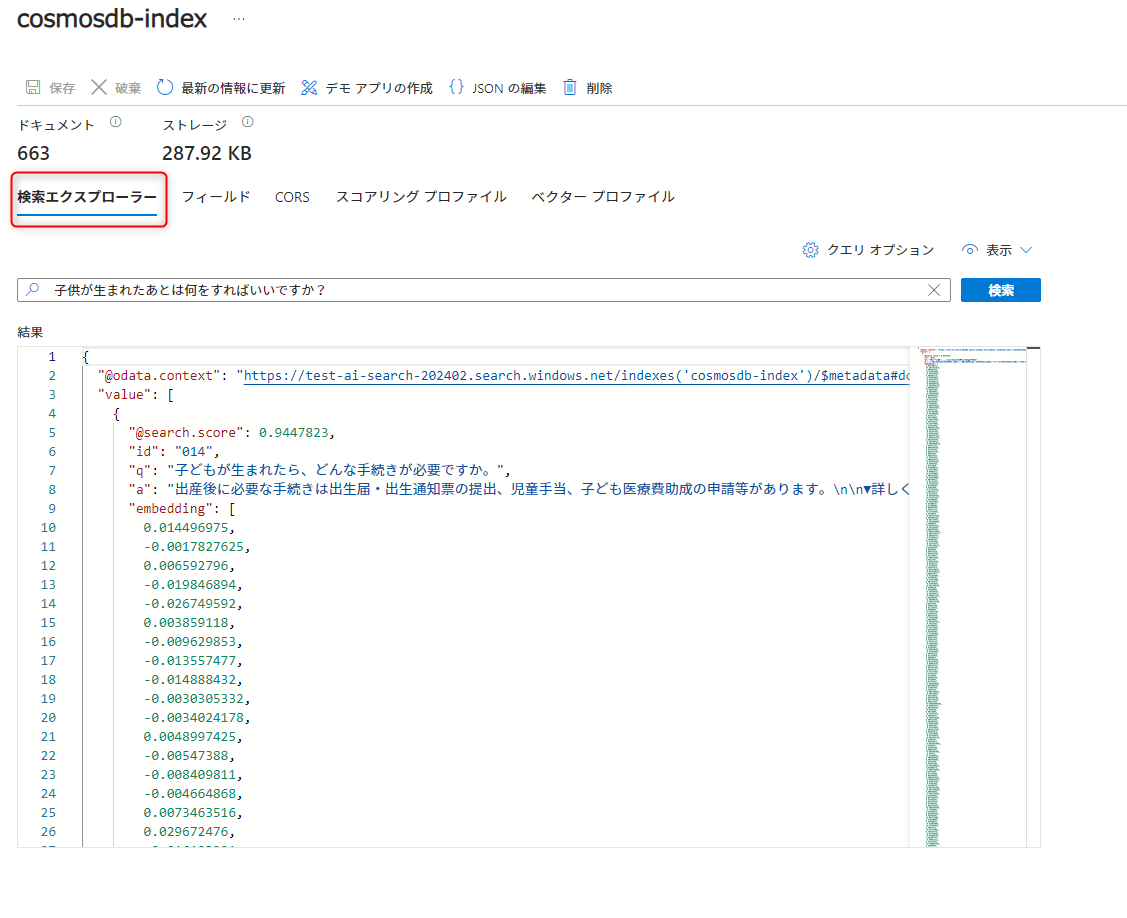
しっかり埋め込みが生成され、検索できる事が確認できました!
Python SDKを使って検索してみる。
今回、以下を参考にしました。
なお、ここで扱うazure-search-documentsの最新版は現時点ではまだプレビュー版のようです。
pyplでまだリリースされてない為、バイナリからインストールします。
To run the code, install the following packages. This sample currently uses version
11.4.0b12which is a pre-release version. Please note, that integrated vectorization feature is in preview and has not been published to azure-search-documents on pypi. If you'd like to use this feature, please reference the whl file. We hope to publish an updated version soon!
pip install ../whl/azure_search_documents-11.4.0b12-py3-none-any.whl
from azure.search.documents import SearchClient from azure.search.documents.indexes import SearchIndexClient, SearchIndexerClient from azure.search.documents.models import ( QueryAnswerType, QueryCaptionType, QueryLanguage, QueryType, VectorizableTextQuery, ) from azure.core.credentials import AzureKeyCredential from dotenv import load_dotenv import os load_dotenv() service_endpoint = os.getenv("AZURE_SEARCH_SERVICE_ENDPOINT") index_name = os.getenv("AZURE_SEARCH_INDEX_NAME") key = os.getenv("AZURE_SEARCH_ADMIN_KEY") model: str = "text-embedding-ada-002" credential = AzureKeyCredential(key) #%% # 検索 - 全文検索とベクトル検索のハイブリッド検索 (検索クエリのベクトル化は自動で行われる) query="子供が生まれたら何をすればいいでしょうか?" search_client = SearchClient(service_endpoint, index_name, credential=credential) vector_query = VectorizableTextQuery(text=query, k=3, fields="embedding", exhaustive=True) results = search_client.search( search_text=query, vector_queries= [vector_query], select=["q", "a", "id"], top=3 ) for result in results: print(f"id: {result['id']}") print(f"q: {result['q']}") print(f"score: {result['@search.score']}") print(f"a: {result['a']}") print("--------")
id: 014 q: 子どもが生まれたら、どんな手続きが必要ですか。 score: 0.029653679579496384 a: 出産後に必要な手続きは出生届・出生通知票の提出、児童手当、子ども医療費助成の申請等があります。 ... -------- id: 942 q: 子育てはどこに相談すればいいですか? score: 0.029286926612257957 a: (自治体の担当課や子育てセンター等)では育児全般の相談を実施しています。 また、(自治体の担当課や子育てセンター等)では子どもの発達や育児について、不安や悩みなどの相談に応じています。 ... -------- id: 425 q: 子どもが生まれたら、どのような手当がありますか。 score: 0.029213953763246536 a: 子どもの手当・助成としては、児童手当と子ども医療費助成制度があります。 ... --------
全文検索とベクトル検索のハイブリッド検索が実行できましたね! (割愛してますが、ベクトル検索だけのパターンと比較すると違いが分かります。)
セマンティックランカー機能を使って検索してみる
もう一度、全文検索とベクトル検索のハイブリット検索を実行します。
今回は上位5件取得します。
query="第一子を授かりました。まずなにをすればいいでしょうか?" search_client = SearchClient(service_endpoint, index_name, credential=credential) vector_query = VectorizableTextQuery(text=query, k=5, fields="embedding", exhaustive=True) results = search_client.search( search_text=query, vector_queries= [vector_query], select=["q", "a", "id"], top=5 ) for result in results: print(f"id: {result['id']}") print(f"q: {result['q']}") print(f"score: {result['@search.score']}") print(f"a: {result['a']}") print("--------") print("\n")
id: 070 q: 第2子出生後の児童手当の手続きを教えてください。 score: 0.022528409957885742 a: 「児童手当・特例給付 額改定認定請求書」を○○市のホームページよりダウンロードしていただき、必要事項を記入の上、(自治体の担当課等の名称)へ郵送又はご持参ください。 ... -------- id: 938 q: 児童手当がもらえる月を教えてください score: 0.019209228456020355 a: 児童手当は、認定請求をした月の翌月分から支給を開始し、原則として、毎年2・6・10月にそれぞれ前月分までが支払われます。 -------- id: 425 q: 子どもが生まれたら、どのような手当がありますか。 score: 0.01903633587062359 a: 子どもの手当・助成としては、児童手当と子ども医療費助成制度があります。 ... -------- id: 930 q: 子どもの手当にはどんなものがありますか? score: 0.018699726089835167 a: 子どもの手当についてはこちらをご覧ください。 ... -------- id: 014 q: 子どもが生まれたら、どんな手続きが必要ですか。 score: 0.0180612001568079 a: 出産後に必要な手続きは出生届・出生通知票の提出、児童手当、子ども医療費助成の申請等があります。 ... --------
“第一子を授かりました。まずなにをすればいいでしょうか?" という問いに対して、
「第2子出生後の児童手当の手続きを教えてください。」「児童手当がもらえる月を教えてください」「子どもが生まれたら、どのような手当がありますか。」が上位に来ています。
文脈的に本来は「子どもが生まれたら、どんな手続きが必要ですか。」の回答を上位にもっていきたいところです。
そこでセマンティック構成を設定してみます。
セマンティックランカーを有効にするには、「セマンティックランカー」からプランを選択して有効化しておく必要があります。また、AI SearchのプランがBasic以上でないといけないので注意です。
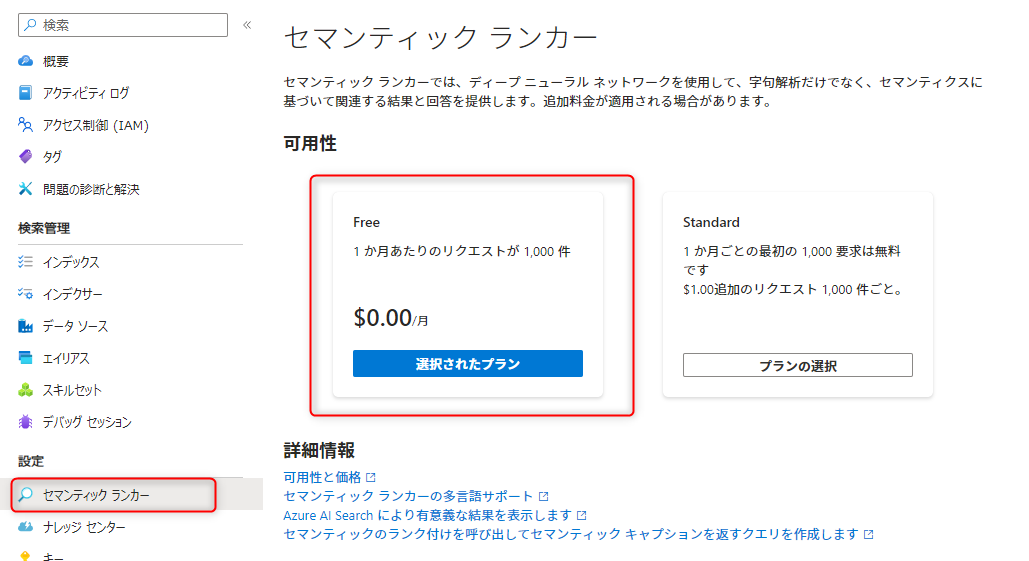
AI Searchの「インデックス」> 「セマンティック構成」から「セマンティック構成の追加」を選択します。
構成には「コンテンツフィールド」を設定してみます。
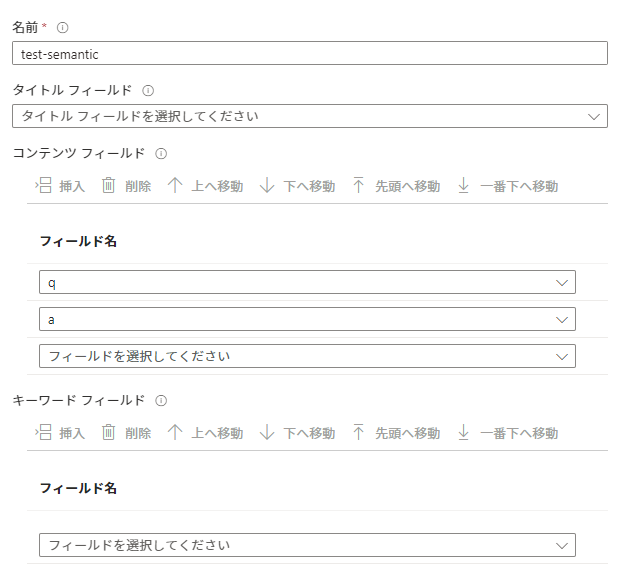
| プロパティ | 特性 |
|---|---|
| タイトルフィールド | 短い文字列 (理想的には 25 語以下)。 このフィールドは、ドキュメントのタイトル、製品の名前、または一意の ID である場合があります。 適切なフィールドがない場合は、空白のままにします。 |
| コンテンツフィールド | 自然言語形式のテキストのより長いチャンク。機械学習モデルで最大トークン入力制限が適用されます。 一般的な例としては、ドキュメントの本文、製品の説明、またはその他の自由形式のテキストがあります。 |
| キーワードフィールド | ドキュメントのタグなどのキーワードのリスト、または項目のカテゴリなどの記述用語。 |
設定が終わったら「保存」を選択します。
セマンティックランカーを用いた検索をしてみましょう。
#検索タイプをセマンティックに変更 query = "第一子を授かりました。まずなにをすればいいでしょうか?" search_client = SearchClient(service_endpoint, index_name, AzureKeyCredential(key)) vector_query = VectorizableTextQuery(text=query, k=5, fields="embedding", exhaustive=True) results = search_client.search( search_text=query, vector_queries=[vector_query], select=["id", "q", "a"], query_type=QueryType.SEMANTIC, query_language=QueryLanguage.JA_JP, semantic_configuration_name='test-semantic', query_caption=QueryCaptionType.EXTRACTIVE, query_answer=QueryAnswerType.EXTRACTIVE, top=5 ) for result in results: print(f"id: {result['id']}") print(f"q: {result['q']}") print(f"Reranker Score: {result['@search.reranker_score']}") print(f"a: {result['a']}") captions = result["@search.captions"] if captions: caption = captions[0] if caption.highlights: print(f"Caption: {caption.highlights}\n") else: print(f"Caption: {caption.text}\n") print("--------") print("\n")
id: 014 q: 子どもが生まれたら、どんな手続きが必要ですか。 Reranker Score: 1.7391620874404907 a: 出産後に必要な手続きは出生届・出生通知票の提出、児童手当、子ども医療費助成の申請等があります。 ... Caption: 子どもが生まれたら、どんな手続きが必要ですか。. 出産後に必要な手続きは出生届・出生通知票の提出、児童手当、子ども医療費助成の申請等があります。 ... -------- id: 942 q: 子育てはどこに相談すればいいですか? Reranker Score: 1.4356616735458374 a: (自治体の担当課や子育てセンター等)では育児全般の相談を実施しています。 また、(自治体の担当課や子育てセンター等)では子どもの発達や育児について、不安や悩みなどの相談に応じています。 ... Caption: 子育てはどこに相談すれば<em>いいですか</em>?. (自治体の担当課や子育てセンター等)では育児全般の相談を実施しています。 ... -------- id: 944 q: 子どもの発育に不安があるのですが、どうすればいいですか? Reranker Score: 1.4214919805526733 a: (子どもの発達について相談できる場所について記載してください。) ... Caption: 子どもの発育に不安があるのですが、<em>どうすればいいですか?</em> . (子どもの発達について相談できる場所について記載してください。 ... -------- id: 058 q: 養育医療の申請は誰がすればいいのですか? Reranker Score: 1.316176414489746 a: 養育医療の申請は、保護者が、お子さんの住所地の保健所に申請します。 Caption: <em>養育医療の申請</em>は誰がすればいいのですか?.<em> 養育医療の申請</em>は ... -------- id: 425 q: 子どもが生まれたら、どのような手当がありますか。 Reranker Score: 1.3000918626785278 a: 子どもの手当・助成としては、児童手当と子ども医療費助成制度があります。 ... Caption: 子どもが生まれたら、どのような手当がありますか。. 子どもの手当・助成としては、児童手当と子ども医療費助成制度があります。 ... --------
上位に「子どもが生まれたら、どんな手続きが必要ですか。」「子育てはどこに相談すればいいですか?」「子どもの発育に不安があるのですが、どうすればいいですか?」が来るようになりました。 より文脈の背後にある不安感に寄り添った形の回答になったように感じます。
セマンティックアンサーが取得できているか確認してみます。
semantic_answers = results.get_answers() if len(semantic_answers) != 0: for answer in semantic_answers: if answer.highlights: print(f"Semantic Answer: {answer.highlights}") else: print(f"Semantic Answer: {answer.text}") print(f"Semantic Answer Score: {answer.score}\n") else: print("No semantic answers found")
No semantic answers found
セマンティックアンサーは得られていませんでした。
セマンティックランカーとは?
そもそもセマンティックランカーとはなんでしょうか。
AI Searchのセマンティックランカーとはクエリに対するセマンティック(意味) 関連性に基づいて結果を再ランク付けするAI Search独自の機能です。 「セマンティックランキング」、「セマンティックアンサー」「セマンティックキャプション」「セマンティックハイライト」の機能群を指します。
| 機能 | 説明 |
|---|---|
| セマンティック ランキング | クエリのコンテキストまたはセマンティックの意味を利用して、事前にランク付けされた結果に対して新しい関連スコアを計算します。 |
| セマンティック キャプション/セマンティックハイライト | コンテンツを最もよく要約している逐語的な文やフレーズをドキュメントから抽出し、スキャンを簡単にするために重要な部分を強調表示します。 結果を要約するキャプションは、個々のコンテンツ フィールドが検索結果ページに対して高密度である場合に便利です。 強調表示されたテキストにより、最も関連性の高い用語とフレーズが目立つため、ユーザーはその一致が関連していると見なされた理由を迅速に判断できます。 |
| セマンティックアンサー | セマンティック クエリから返される省略可能な追加のサブ構造体。 これにより、質問のようなクエリに直接回答することができます。 ドキュメントには、回答の特性を持つテキストが含まれている必要があります。 |
セマンティック ランカーは新しいテクノロジであるため、できることとできないことについて期待を設定することが重要です。 "できること" は、次のようなことです。
- セマンティック的に元のクエリの意図に近い一致を昇格させます。
- キャプションおよび回答として使用できる文字列を見つけ出します。 キャプションと回答は応答で返され、検索結果ページに表示できる文字列が検出されます。
セマンティック ランク付けで "できない" ことは、コーパス全体に対してクエリを再実行して、セマンティックな関連がある結果を検出することです。 セマンティック ランク付けでは、既定のランク付けアルゴリズムによってスコアリングされた上位 50 個の結果で構成される既存の結果セットが再ラン> ク付けされます。 さらに、セマンティック ランク付けで新しい情報や文字列を作成することはできません。 キャプションと回答は、コンテンツから逐語的に抽出されるので、結果に回答のようなテキストが含まれていない場合、その言語モデルではキャプションや回答は生成されません。
ドキュメントに記載の通り、セマンティックランカーは検索クエリで既に取得された上位50件の結果をより関連性のある順に再配置する機能の為、新たな結果をコーパス全体から探し出したり、新しい情報を作成したりすることはできないという事ですね。
セマンティックアンサー
検索ドキュメントからの 1 つ以上の逐語的な節で構成され、質問のようなクエリに対する回答として作成されます。 回答を返すには、回答の言語特性を持つ語句または文が検索ドキュメントに存在する必要があります。 また、クエリ自体を質問として表す必要があります。Azure AI Search は、機械読み取りの理解モデルを使用して最適な回答を認識し選択します。 このモデルでは、利用可能なコンテンツから一連の考えられる回答が生成され、十分な信頼度レベルに達すると、いずれかが回答として提案されます。
先程の回答ではセマンティックアンサーは得られませんでした。 セマンティックアンサーを得るには、「回答の言語特性を持つ語句または文が検索ドキュメントに存在し、検索クエリ自体が質問として提示されている必要があり、かつ十分に高い信頼水準に達するとき」だけのようです。 なので、出現しない場合もあるようです。
セマンティックキャプション
セマンティックアンサーが得られなった場合でも、セマンティックキャプションの機能で、関連性の高い検索結果の一部を抽出することができます。 回答に近いと思われる部分には自動的にハイライトを付加します。
先程の検索ではセマンティックアンサーは得られなかったものの、セマンティックキャプションは得られました。<em>タグで囲まれているのがハイライト箇所になります。
Caption: 子育てはどこに相談すれば<em>いいですか</em>? Caption: 子どもの発育に不安があるのですが、<em>どうすればいいですか?</em>
「どうすればいいですか?」にハイライトが当たっています。 質問の背景を鑑みたように思えたのはこの機能によるものだったようです。
セマンティックランキング
Microsoft の自然言語の理解を使用して検索結果を再スコア付けし、セマンティック関連性の高い結果を一覧の先頭に昇格させます。 スコアリングは、キャプションと、256 のトークン長を埋める要約文字列の中の他のあらゆるコンテンツに対して行われます。
キャプションは、指定されたクエリに対して相対的な概念とセマンティックの関連性に対して評価されます。
@search.rerankerScore が各ドキュメントに、指定のクエリのドキュメントのセマンティック関連性に基づいて割り当てられます。 スコアの範囲は 4 から 0 (高から低) です。スコアが高いほど関連性が高いことを示します。
一致は、スコア順に一覧表示され、クエリ応答ペイロードに含められます。 ペイロードには、回答、プレーンテキスト、強調表示されたキャプション、select 句で取得または指定されたフィールドが含まれます。
セマンティックランキングで検索結果を再スコア付した結果、先程の検索ではより背景に沿った回答ができたようです。
他にもAI Searchには機能がもりだくさんです。
中でも現在パブリックプレビュー中の「ベクトル統合機能」ではAzure Blob Storageをデータソースとして、格納されているPDFやテキストコンテンツにチャンキングと埋め込み、そして今回おこなったインデクサーの定義や組み込みスキルの定義などを全て自動でおこなってくれます。
なんて便利なのでしょう...!
さいごに
今回は、CosmosDBをデータソースとしてAzure AI SearchのAzure OpenAI Embedding スキルを試してみました。 パブリックプレビュー中の機能含め、他にも豊富な機能が備わっているので今後も色々試していこうと思います。
拙い内容で恐縮ではありますが、最後までご覧頂き有難うございました!🙏
サービス一覧 www.alterbooth.com cloudpointer.tech www.alterbooth.com


