こんにちは、先日妻の誕生日に娘が朝早起きして妻には内緒で部屋を折り紙などで飾り付けていたのですが、その前日に妻に「明日のママの誕生日、私は普通におめでとうってだけ言うからね」と言っていてそんな勘ぐられそうなこと言わなければいいのにと思った木村です。
現在パブリックプレビューで提供されているAzure OpenAI Studioならびに独自データをOpenAIから利用する機能を使って、独自データを利用するLLMチャットアプリケーションを作ってみたので、それについて書こうと思います。なお、アプリケーション自体はMicrosoft社から提供されるサンプルチャットアプリケーションそのままで、OpenAIの呼び出し方を独自に調整したということになります。
Azure OpenAI Studioについて
Azure OpenAI Studioは、Azure OpenAI Serviceを利用した開発を支援する、Webベースの開発環境です。モデルのデプロイ管理、デプロイしたモデルの動作検証、システムプロンプトの調整、Azure AI Searchなどを用いた独自データへのアクセス、サンプルチャットアプリケーションのAppServiceへのデプロイなど、多くの機能を直感的に利用できるようになっています。
今回はこちらを利用して、独自データを利用するLLMチャットアプリケーションを作成してみます。なお、画面は2024年2月5日現在のものです。Azure OpenAI Studioはパブリックプレビューの機能でもあるので、皆様が本記事を参照された時点では画面や機能は大きく変わっている可能性もあるのでご了承ください。
LLMチャットアプリケーションから独自データを利用する
今回作成する「独自データを利用するLLMチャットアプリケーション」というのは、多少語弊はありますが、「社内文書の内容も回答に利用するChatGPT」みたいなものです。
基本的には、OpenAIのモデルとやり取りをする際に、独自のデータをOpenAIが参照できるようにやり取りの中に含めてあげるということで実現します。これまでは、これを実現するには自身でプログラムを書いて独自データを含めたプロンプトを作成したり、LangChainやSemantic Kernelといったフレームワークでこの工程を抽象化するといったことが必要でした。
これがAzure側で準備された機能の呼び出しだけで簡単に実現でき、しかもそのセットアップもOpenAI Studioを使うと簡単にできるというのは嬉しいですね。
なお、先日弊社の池田が、AI SearchとCosmos DBを組み合わせてベクター検索で検索を行うというブログを書いていますので是非こちらも併せてご一読ください。
今回の構成は、池田のブログとは違い、Blobにアップロードされたファイルの情報をAI Searchでインデックス化してOpenAIと組み合わせるようにします。
OpenAIのリソースを作成
Azure OpenAIのリソースを作成します。azure portalの「リソースの作成」で、「openai」で検索します。
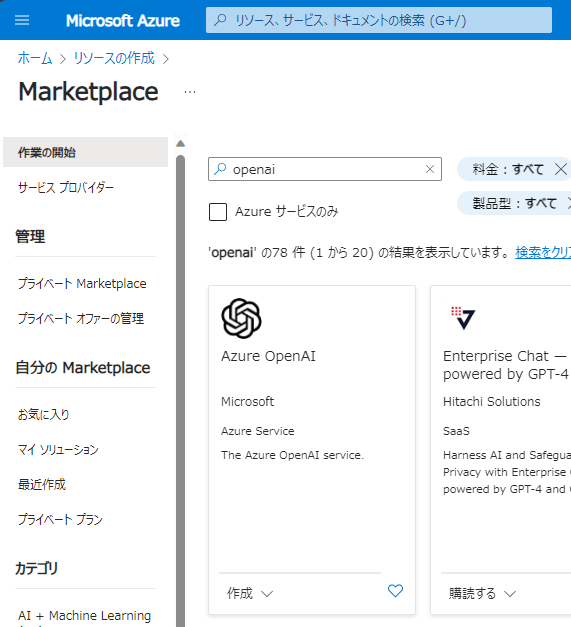
ベクター検索のために埋め込みモデル(text-embedding-ada-002)が必要になるので、このモデルがサポートされているリージョンにリソースを作成します。
こちらのドキュメントに情報がありますが、今回は米国東部リージョンを使うことにします。
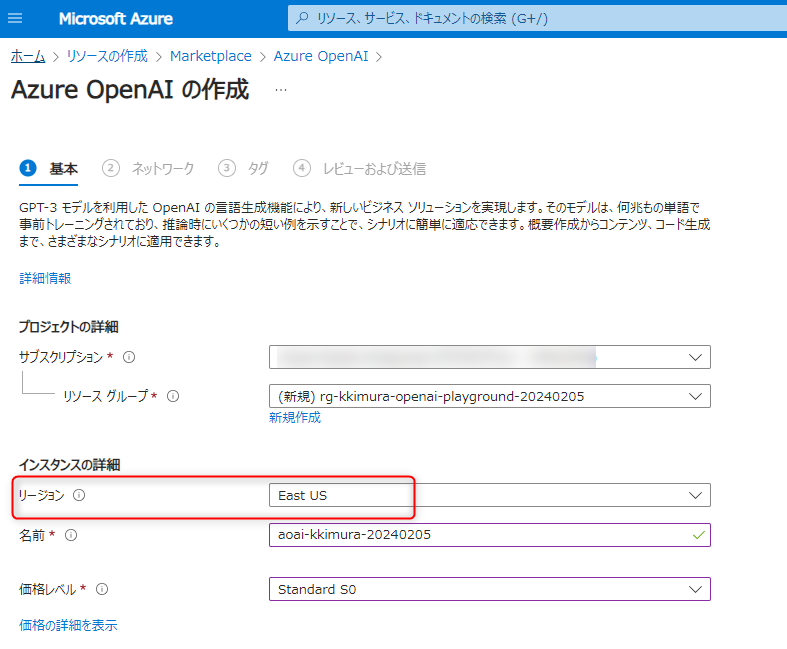
ネットワークの制限は、今回は「インターネットを含むすべてのネットワークがこのリソースにアクセスできます」を選択します。
「確認および作成」に進み、「作成」を押します。
AI Searchのリソースを作成
AI Searchのリソースを作成します。同じくリソースの作成から「AI Search」で検索します。
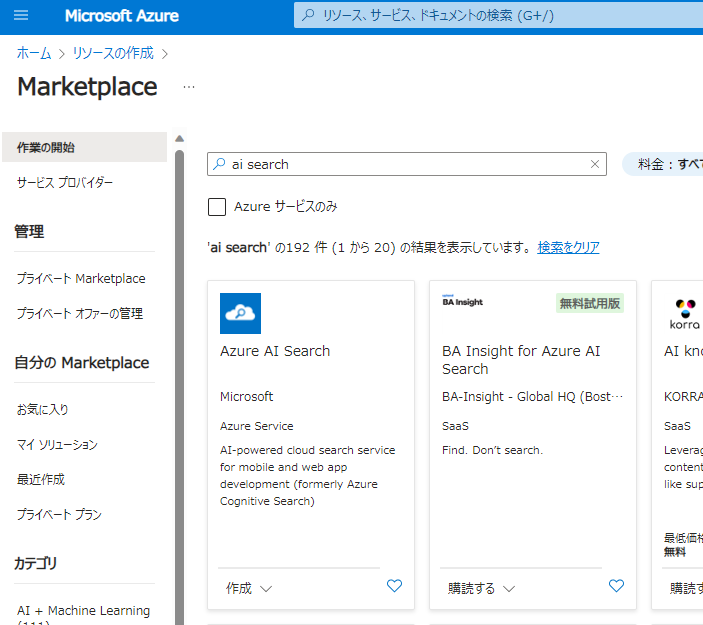
OpenAI Studioからの統合を行うには、Basic(基本)以上の価格レベルが必要になりますので、ここではBasicを選択します。
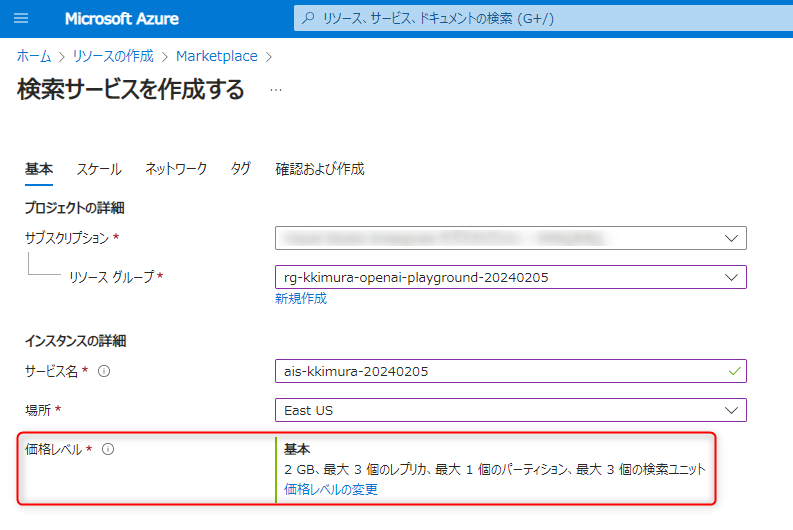
「確認および作成」に進み、「作成」を押します。
ストレージアカウントを作成
OpenAIから参照する独自データをAzureにアップロードしますが、そのファイルを置くためのBlobが必要なので、ストレージアカウントを作成します。ストレージアカウントの設定はデフォルトのままで問題ありませんのでここでは作成手順は割愛します。また、この時点でBlobコンテナの作成は不要です。
モデルのデプロイ
これでリソースの準備は終了です。早速OpenAI Studioにアクセスしてみましょう。
OpenAI Studioのポータルに直接アクセスしてもいいのですが、ここでは先ほど作成したAzure OpenAIのリソースからアクセスしてみましょう。左のメニューの「リソース管理>モデルデプロイ」を選択すると、この機能がOpenAI Studioに移動したことが表示されます。「展開の管理」を押しましょう。
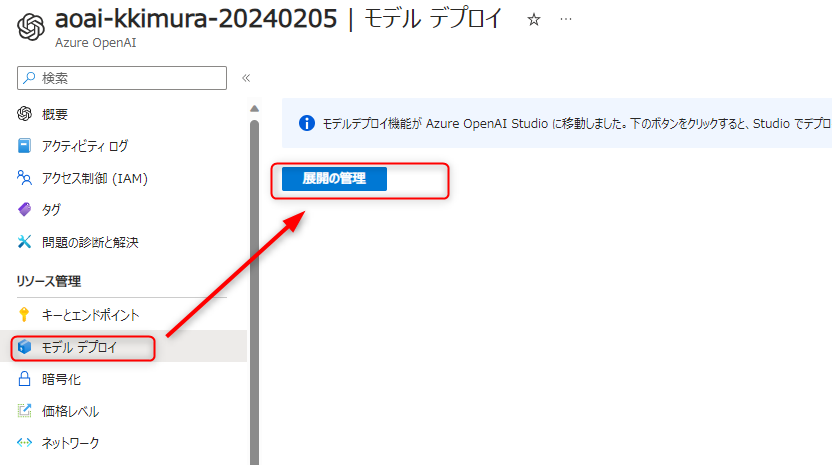
「展開の管理」を押すとサインインを求められるので、azure portalにサインインしたのと同じアカウント情報でサインインしましょう。以下のようなページが表示されると思いますので、メニューの「管理>デプロイ」(既に選択された状態のはずです)から「新しいデプロイの作成」を押してモデルをデプロイしましょう。
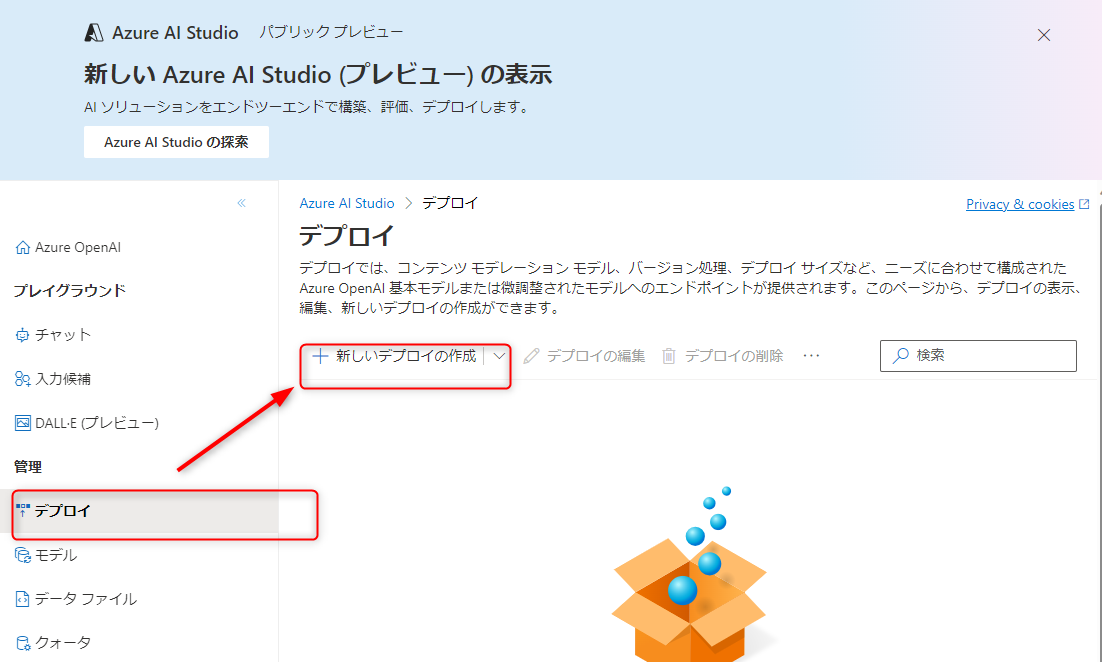
今回はLLMとしてgpt-35-turboを、埋め込みのためにtext-embedding-ada-002を使用します。両方のモデルを選択し、デプロイします。
恐らくデプロイはすぐに行われ、以下のようにデプロイしたモデルが一覧表示されるはずです。
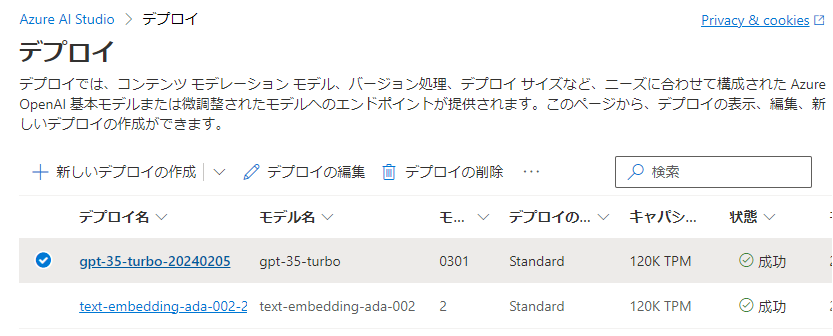
プレイグラウンドでモデルにアクセスする
続いて、OpenAI Studioの「プレイグラウンド」を使ってみましょう。プレイグラウンドは、デプロイしたモデルを使ったプログラムの開発を支援する機能です。例えばLLMモデルであれば実際にチャットをしながらプロンプトを調節したり、独自データを埋め込んだりして動作を確かめ、その結果を呼び出すプログラムのサンプルを作ってもらったり、チャットアプリをそのままAppServiceに展開することが可能です。
早速チャットプレイグラウンドに移動して、この状態でgpt-35-turboに何か聞いてみましょう。

「OpenAIとは何ですか?」と聞いてみましたが、ちゃんと回答がありました。これだけでも既にChatGPTっぽいですね。
では、gpt-35-turboが知らなさそうなこととして、私のことを聞いてみます。
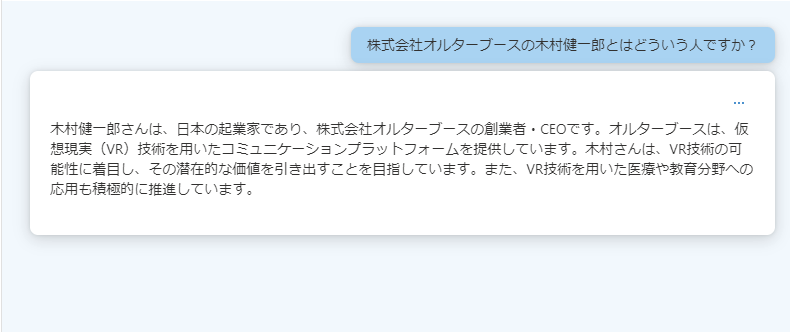
・・はい、だいぶ嘘ですね(笑)
システムプロンプトを変更して、知らないことは知らないと答えてもらうようにしましょう。チャットの画面を上にスクロールすると、「アシスタントのセットアップ」という機能があります。ここでシステムメッセージに「あなたは誠実なAIアシスタントです。自身が知らないことについては「知らない」と答えてください。」と入力し、「変更を適用する」を押します。
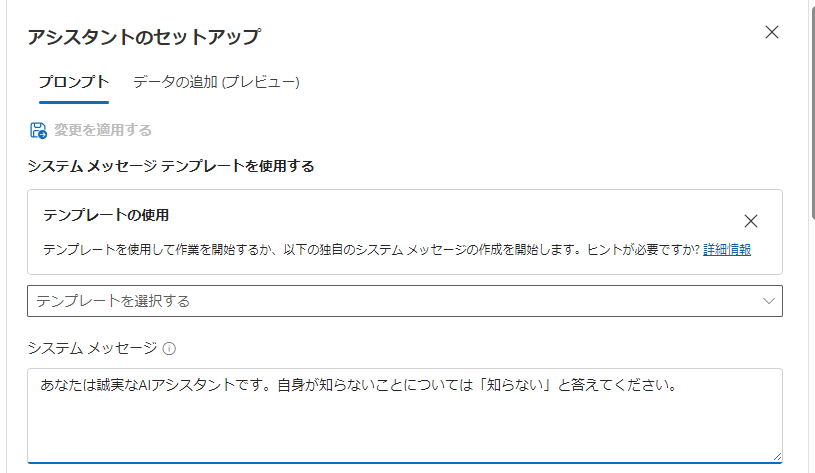
このシステムプロンプトには色々なテンプレートも準備されていますので、用途に応じて参考にしてみてください。
では、このシステムプロンプトで先ほどと同じことを聞いてみましょう。
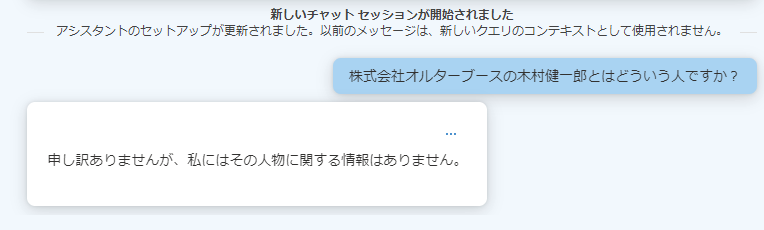
知らない、と回答されました。それはそれでちょっと悲しいですが(笑)
独自データを利用するように構成する
それでは独自データを利用して、ちゃんと私のことを回答してくれるようにしてみましょう。
以下の発表資料(PDF)を使うと、私の自己紹介が入っているのできっとちゃんと回答してくれるはずです。
チャットの画面を上にスクロールし、先ほどシステムプロンプトを設定した画面を表示します。すると「データの追加(プレビュー)」というタブがあるのでこちらにアクセスし、「データソースの追加」を押します。
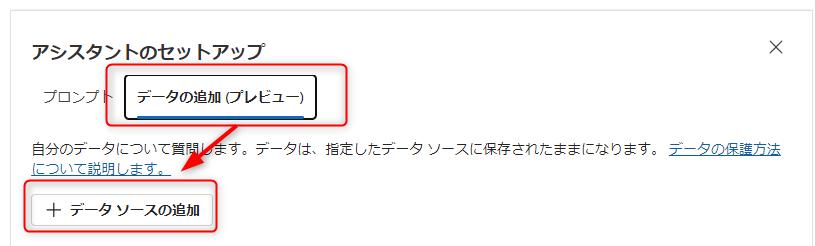
データソースには以下の物が選択できます。
- Azure AI Search
- Azure Blob Storage
- Azure Cosmos DB for MongoDB vCore
- URL/web address
- Upload files
今回はデータのアップロードとインデックス作成を一度に行うので「Upload files」を選択します。アップロード先のストレージアカウントを選択します。
また、OpenAIサービスがストレージアカウントにアクセスできるようにするために、「CORSをオンにする」を押します。
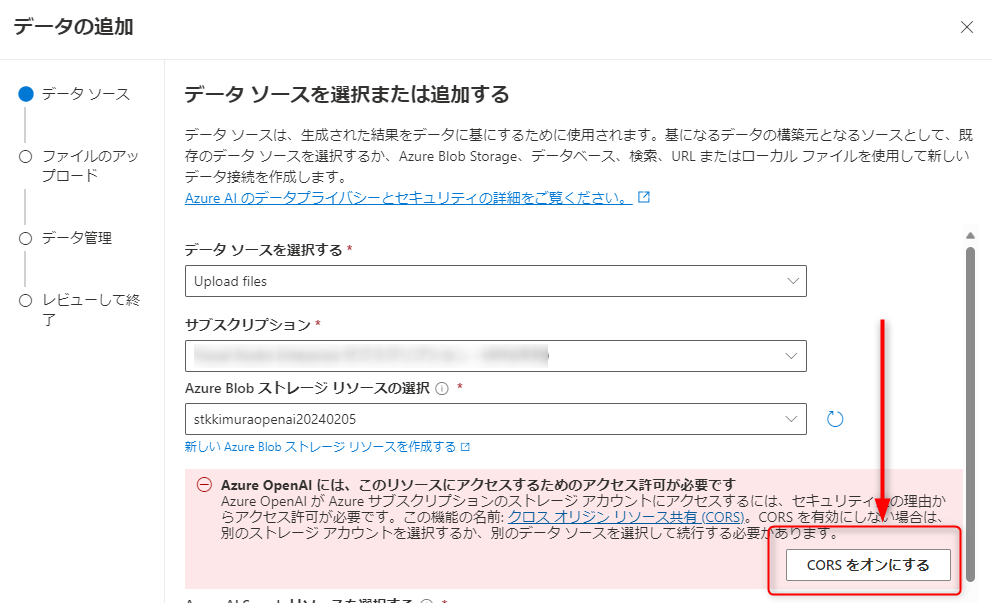
続いて、Azure AI Searchリソースの設定をします。AI Searchのリソースを選択し、インデックス名を入力し、「ベクトル検索をこの検索リソースに追加します」にチェックを入れます。
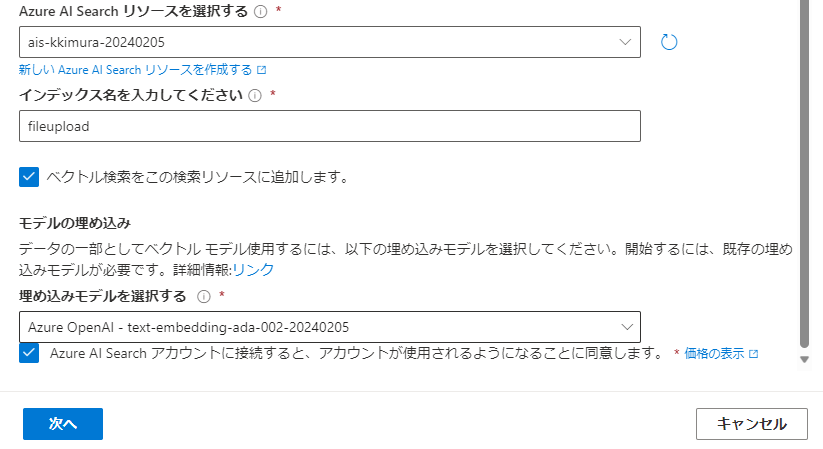
チェックを入れると「モデルの埋め込み」に関する設定が下記の通り表示されるので、デプロイしておいたtext-embedding-ada-002のモデルを選択し、「Azure AI Searchアカウントに接続すると、アカウントが使用されるようになることに同意します」にチェックを入れます。
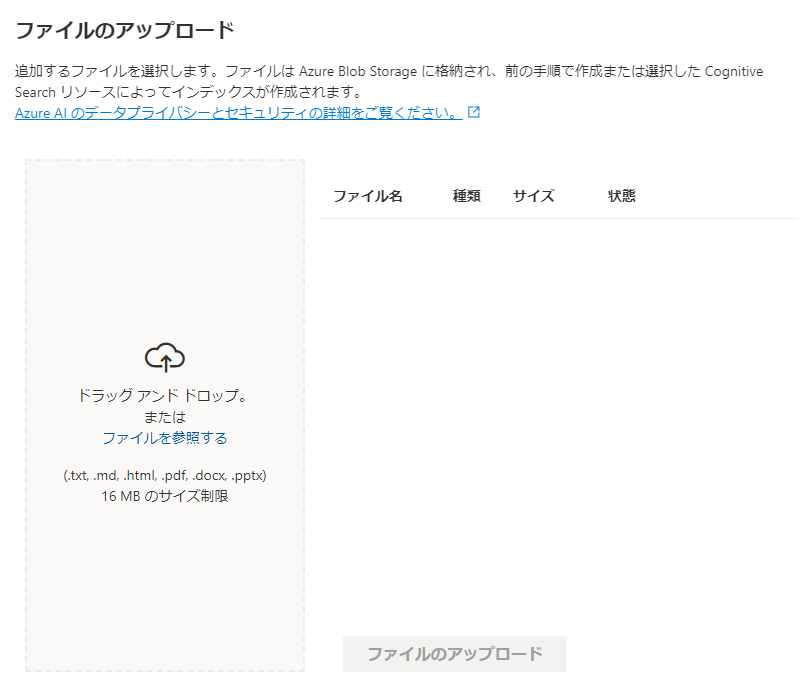
「次へ」を押すと、ファイルのアップロード画面になるので、ここにファイルをドラッグ&ドロップするか、参照して選択します。
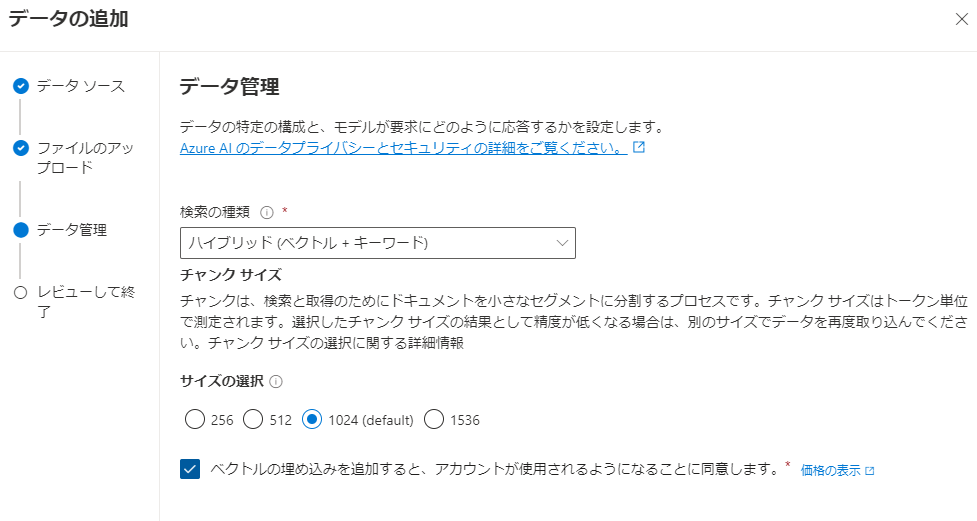
アップロードが完了したら、次へ進み、データ管理の設定をします。検索の種類は「ハイブリッド(ベクトル+キーワード)」とし、「ベクトルの埋め込みを追加すると、アカウントが使用されるようになることに同意します」にチェックを入れます。
確認して閉じると、「インジェストが進行中です」と出るのでしばらく待ちます。
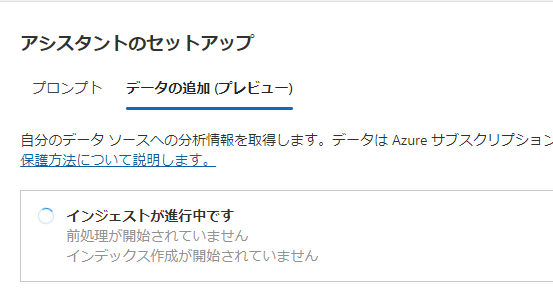
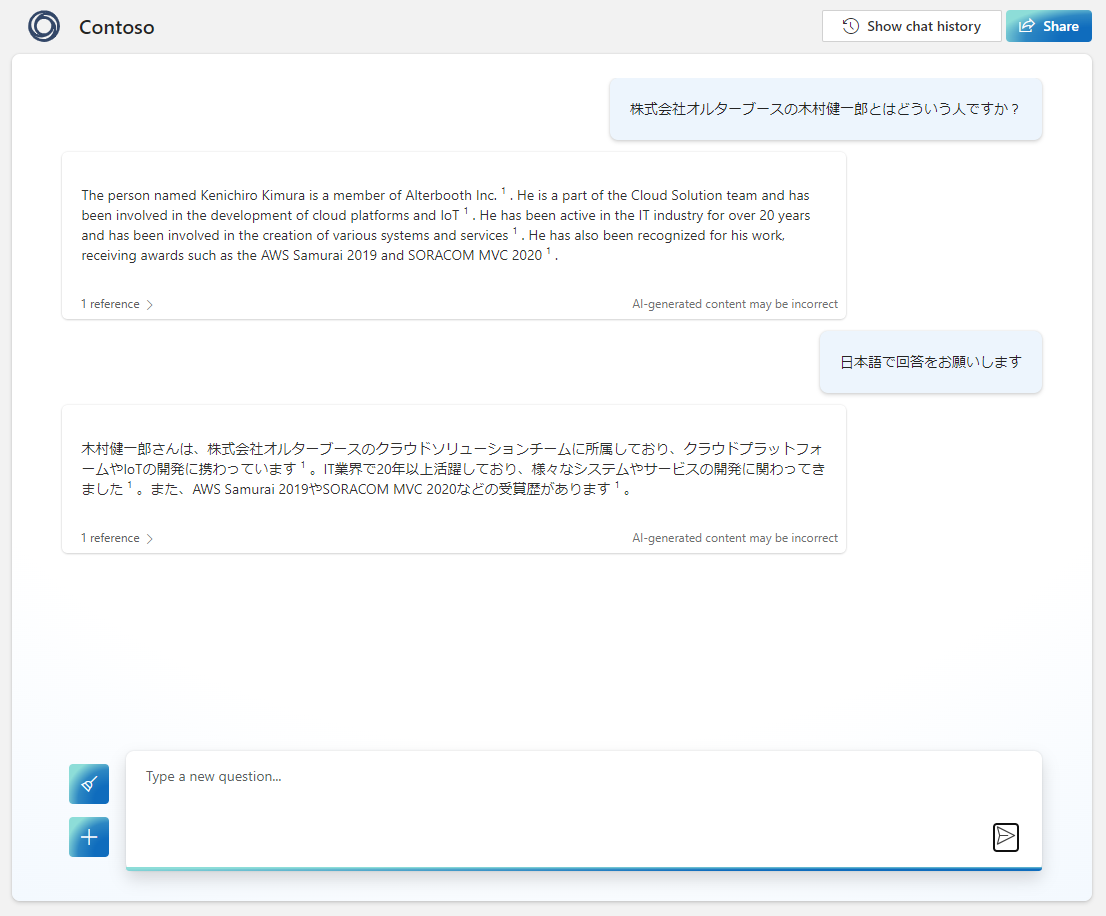
完了したら、早速先ほどと同じことを聞いてみましょう。
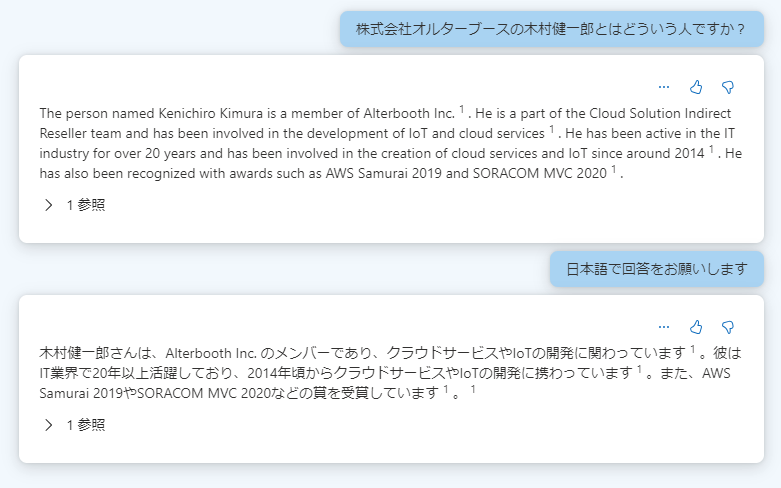
何故か最初の回答が英語だったので追加の質問で日本語にしてもらいましたが、ちゃんと回答してくれました!
アプリのデプロイ
せっかくなのでこのアプリケーションをAppServiceにデプロイしてみましょう。チャットプレイグラウンドの右上の「配置先」から「新しいWebアプリ」を選択します。
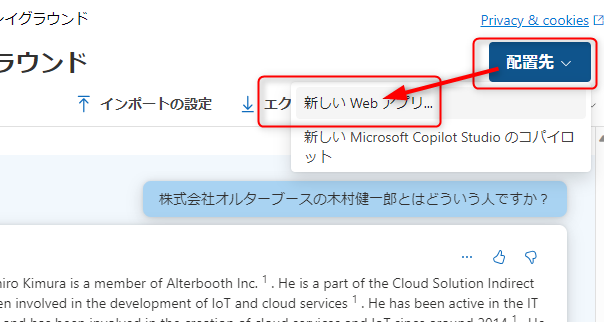
「新しいWebアプリを作成する」を選択し、必要事項を選択していきます。チャットの履歴を有効にすると、履歴を保存するCosmosDBも作成されます。
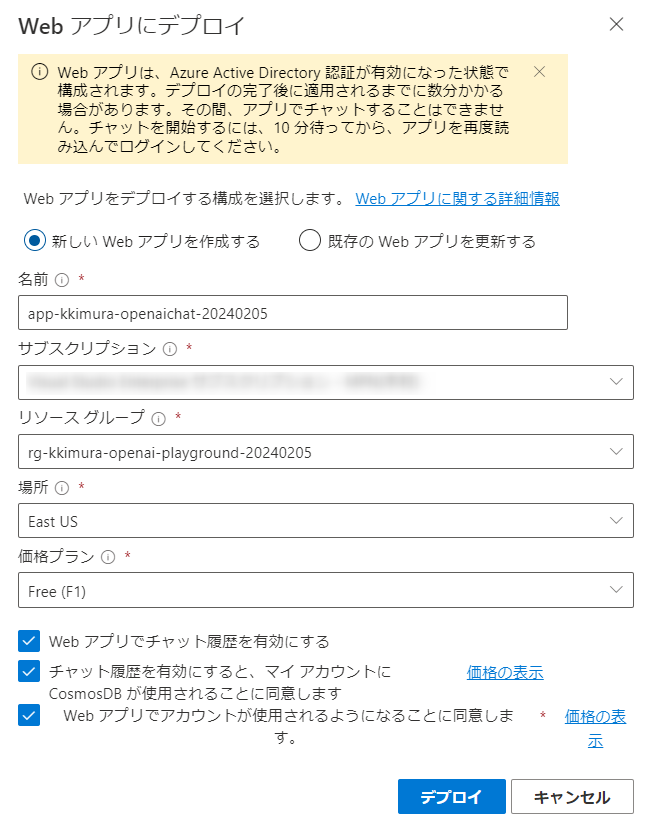
デプロイが終了したら、アプリにアクセスしてみましょう。先ほどのボタンの横に「Webアプリを起動する」というボタンが増えますので、こちらを押します。
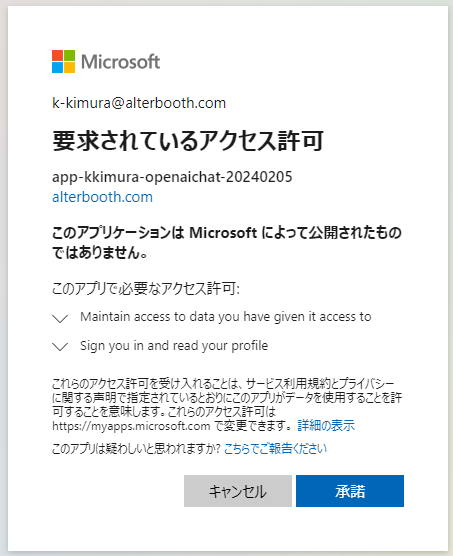
Entra IDでの認証(EasyAuth)が設定されているので、サインインします。初回は以下のようにアクセス許可を求められるので「承諾」を押します。
いい感じに動いていますね!
サンプルコード
参考までに、このチャットを実現するサンプルコードも作ってくれるので見てみましょう(分量があるのでコメントを省略しました)。
import openai, os, requests openai.api_type = "azure" openai.api_version = "2023-08-01-preview" # Azure OpenAI setup openai.api_base = "https://*****.openai.azure.com/" # Add your endpoint here openai.api_key = os.getenv("OPENAI_API_KEY") # Add your OpenAI API key here deployment_id = "gpt-35-turbo-20240205" # Add your deployment ID here # Azure AI Search setup search_endpoint = "https://*****.search.windows.net"; # Add your Azure AI Search endpoint here search_key = os.getenv("SEARCH_KEY"); # Add your Azure AI Search admin key here search_index_name = "fileupload"; # Add your Azure AI Search index name here def setup_byod(deployment_id: str) -> None: class BringYourOwnDataAdapter(requests.adapters.HTTPAdapter): def send(self, request, **kwargs): request.url = f"{openai.api_base}/openai/deployments/{deployment_id}/extensions/chat/completions?api-version={openai.api_version}" return super().send(request, **kwargs) session = requests.Session() # Mount a custom adapter which will use the extensions endpoint for any call using the given `deployment_id` session.mount( prefix=f"{openai.api_base}/openai/deployments/{deployment_id}", adapter=BringYourOwnDataAdapter() ) openai.requestssession = session setup_byod(deployment_id) message_text = [{"role": "user", "content": "What are the differences between Azure Machine Learning and Azure AI services?"}] completion = openai.ChatCompletion.create( messages=message_text, deployment_id=deployment_id, dataSources=[ # camelCase is intentional, as this is the format the API expects { "type": "AzureCognitiveSearch", "parameters": { "endpoint": "$search_endpoint", "indexName": "$search_index", "semanticConfiguration": null, "queryType": "vectorSimpleHybrid", "fieldsMapping": {}, "inScope": true, "roleInformation": "あなたは誠実なAIアシスタントです。自身が知らないことについては「知らない」と答えてください。", "filter": null, "strictness": 3, "topNDocuments": 5, "key": "$search_key", "embeddingDeploymentName": "text-embedding-ada-002-20240205" } } ], enhancements=undefined, temperature=0, top_p=1, max_tokens=800, stop=null, stream=true ) print(completion)
独自データとしてAI Searchのインデックスを使うのはsetup_byod関数の所になりますが、AzureのAPIを呼び出すだけで簡単に実現できていることが分かります。
まとめ
独自データを利用するLLMチャットアプリケーションを作成してみましたが、OpenAI Studioを使うことで非常に簡単に作成できました。
今回はアプリケーションのUIなどはMicrosoftが準備したサンプルそのままですが、独自データを利用するようにOpenAIのLLMを呼び出す部分のサンプルコードも提供されますので、独自のアプリケーションに組み込むのも容易かと思います。
OpenAIを利用するアプリケーションの構築に必要なリソースの作成やAI Searchのインデックス設定などが簡単に行えるので、皆さんも是非OpenAI Studioをお試しいただければと思います。この裏側で実際にはどういう処理(リソースの設定)が行われているのかといったことはまた別の記事で触れられたらと思います。
皆様のお役に立てば幸いです。
サービス一覧 www.alterbooth.com cloudpointer.tech www.alterbooth.com


