こんにちは!オルターブースの木村龍太郎です!
この記事はオルターブース Advent Calendar 2024の15日目の記事です。
最近、RAG(Retrieval Augmented Generation)の構築を行いたく、CosmosDB for NoSQLでベクトル検索を試したいというニーズがありました。
ベクトル ストア - Azure Cosmos DB for NoSQL | Microsoft Learn
そのため、格納したいデータはベクトル化しないとCosmosDBに保存できないので、 その前処理として、Word、Excel、PowerPointなどのさまざまなファイルデータをテキスト化し、Embeddingモデルでデータをベクトル化する必要がありました。
問題
LangChainやOpenAI、Azure Document Intelligenceなどのサービスを利用して、さまざまなファイルをテキスト化する方法があります。 しかし、これらのサービスを利用すると、そのサービスの利用料金がかかります。特に、RAGの要件を満たすパターンでは、大量のデータを処理することが多くなるため、利用料金が高額になる可能性があります。
解決策
そこで登場するのが、マイクロソフトが開発したMarkItDownというライブラリです。
このライブラリは、PDFだけでなく、Word、Excel、PowerPointなどのさまざまなファイル形式を文字起こし(OCR)などの処理をしてMarkdownに変換することができます。 さらに、少ないコードで実行できるため、非常に便利です。そして、マイクロソフト製なので安心して使用できます。
使い方
MarkItDownの使い方は非常に簡単です。
まず、ライブラリをインストールします。
pip install markitdown
その後、少ないコードで実行することができます。
from markitdown import MarkItDown markitdown = MarkItDown() result = markitdown.convert("test.xlsx") print(result.text_content)
結果
試しに自分が前LTをした時のPowerPointを読み込んでみます。
from markitdown import MarkItDown markitdown = MarkItDown() result = markitdown.convert("2023_0829_GEEKERS NITE.pptx") with open("result.txt", "w") as file: file.write(result.text_content)
画像が多い資料だったにもかかわらず一瞬でMarkdownが作成されました。
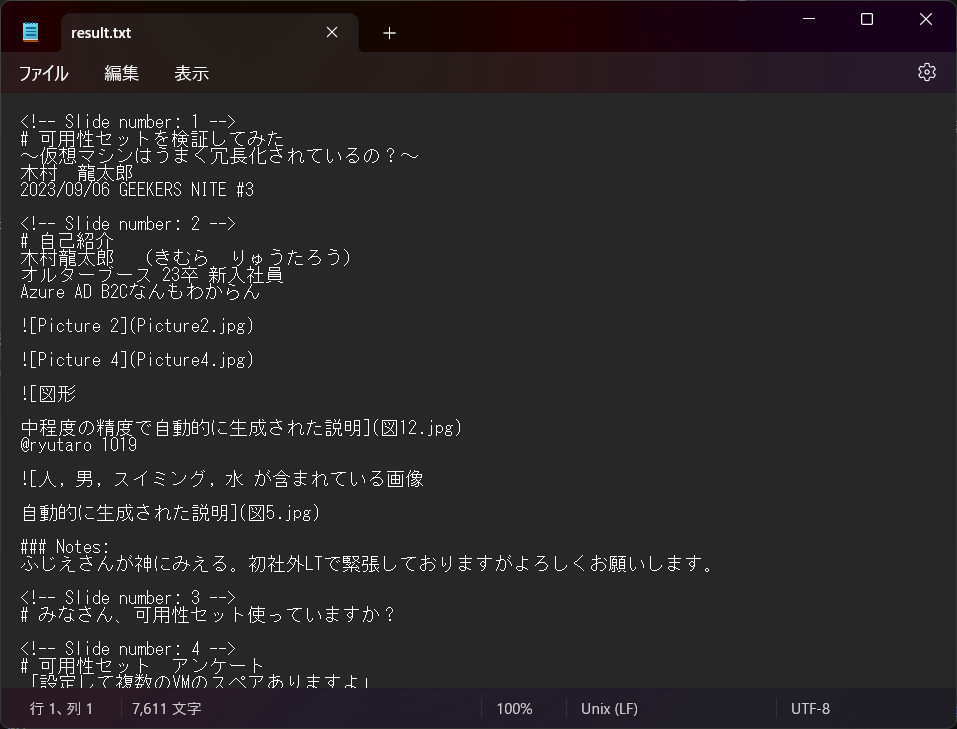
よく読んでみるとわかる通り、PowerPointファイルの場合、スライドのページ数や画像のalt情報も含まれており、整理されていました。
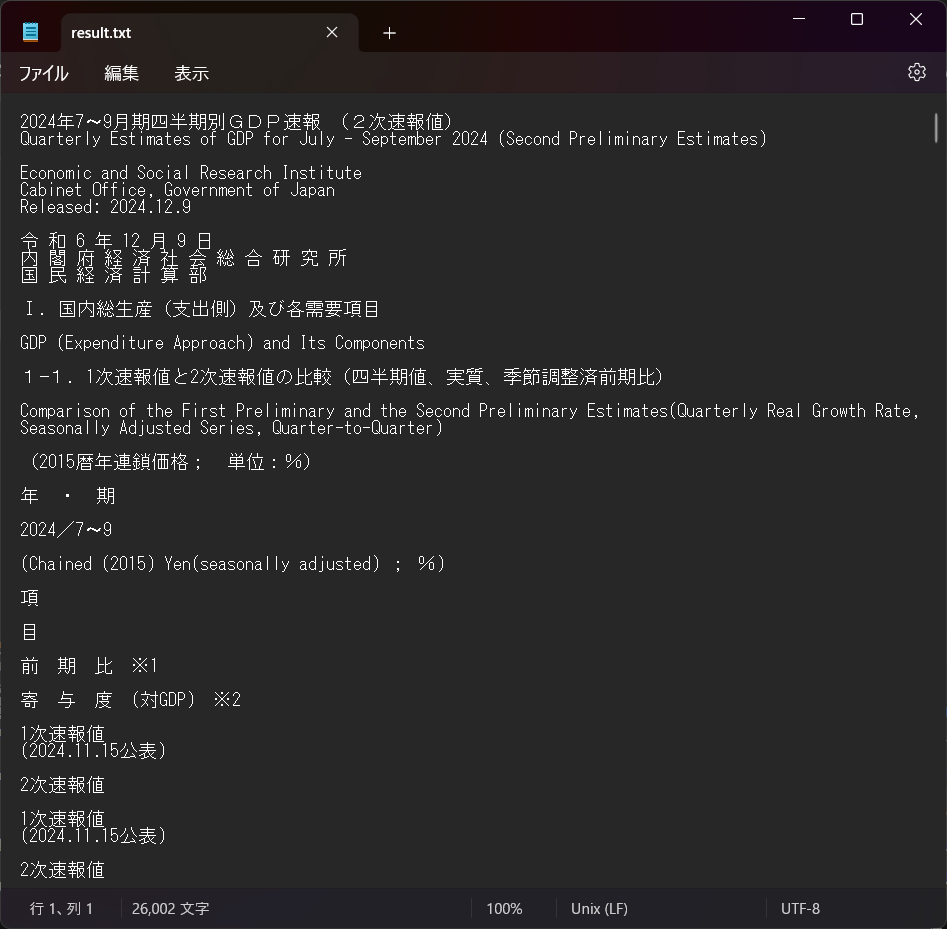
次に以下に掲載された国民経済計算(GDP統計)のPDFファイルも読み込んでみましょう。
日本語のPDFファイルにもかかわらず非常にきれいに文字起こし(OCR)されました。
今後の展望
最初に述べたようにAzure Document Intelligenceを利用すれば楽に処理できる場面もありますが、コストがかかるため、どちらを選ぶかは用途次第です。
RAGの精度を上げるには、データをいかにうまくクレンジングするかもカギになってくるかと思うので、その点にも注力して開発していきたいですね。
MarkItDownを使って、テキスト分析やインデックス作成を効率化してみてはいかがでしょうか?ぜひ試してみてください!
サービス一覧


