
こんにちは、MLBお兄さんこと松村です。
MLB はストーブリーグに突入しましたが、いま一番ホットなのはオークランド・アスレチックスのラスベガス移転がオーナー会議で承認されたという話題ですね。
今回は Azure Cosmos DB for NoSQL のデザインパターン解説記事の第2弾です。
前回は「属性配列 (Attribute Array) パターン」を解説しました。
今回は「データビニング (Data Binning) パターン」について解説をします。
このデザインパターンについては、Cosmos DB の GitHub リポジトリやブログで紹介されていますので、詳しく読みたい方はこちらもご覧ください。
まず「binning」という言葉がピンとこなかったので、辞書を引きます。なるほど、なんとなくイメージがつきました。
binの現在分詞。(ふた付きの大きな)容器
このデザインパターンの特徴としては、データが高頻度で生成され、特定の時間間隔にわたるデータの集約ビューが必要とされる場面で有効な設計パターンであるということです。
これは Azure Cosmos DB がよく採用されるワークロードに当てはめることができます。
それは IoT デバイスから受け取ったデータの保存場所として、Azure Cosmos DB for NoSQL を使うケースです。
様々な場所に設置したセンサーデバイスから送信されるリアルタイムデータを処理する、というのは Azure の各サービスを組み合わせて、よく実践されるアーキテクチャーの一つです。図であらわすとこんな感じです。
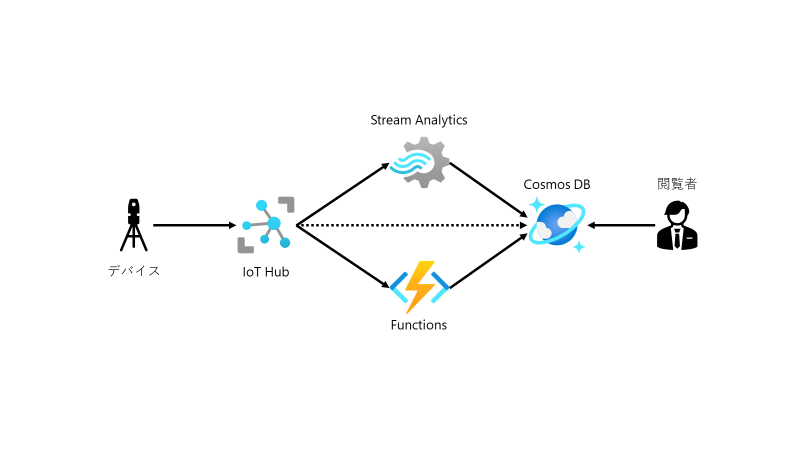
※図中の点線はプレビュー機能です。
- Azure IoT Hub
- Azure Stream Analytics
- Azure Functions
- Azure Cosmos DB
しかしデータはリアルタイムで受け取って処理されるけれども、その集約されたデータを閲覧するのはリアルタイムではなく都度である、という場合もあります。
このようなケースにおいて、データビニングパターンを使用すると良いということです。
「細かいデータを大きな容器に入れる」みたいな意味からきているようです。
そこでデータは2種類にわけてもつことになります。それぞれの JSON の例を載せます。
1.センサーデバイスからのオリジナルのJSONデータ
{ "deviceId": 1, "eventTimestamp": "12/30/2022 10:53:05 PM", "temperature": 71.3, "unit": "Fahrenheit", "receivedTimestamp": "12/30/2022 10:53:05.128 PM" }
2.オリジナルのデータを集約したJSONデータ
{ "deviceId": 1, "eventTimestamp": "12/30/2022 10:53:00 PM", "avgTemperature": 71.2, "minTemperature": 71.1, "maxTemperature": 71.3, "numberOfReadings": 12, "readings": [ { "eventTimestamp": "12/30/2022 10:53:05 PM", "temperature": 71.1 }, { "eventTimestamp": "12/30/2022 10:53:10 PM", "temperature": 71.1 }, // and so on... ], "receivedTimestamp": "12/30/2022 10:54:00 PM" }
2つの JSON の違いは分かりますでしょうか?
集約 JSON データ(2つめ)の readings に、オリジナルの JSON データ(1つめ)が含まれる形になっています。
そのうえで気温等の値を集計し、JSON のプロパティとして設定されています。
図にすると、こんな感じでしょうか。
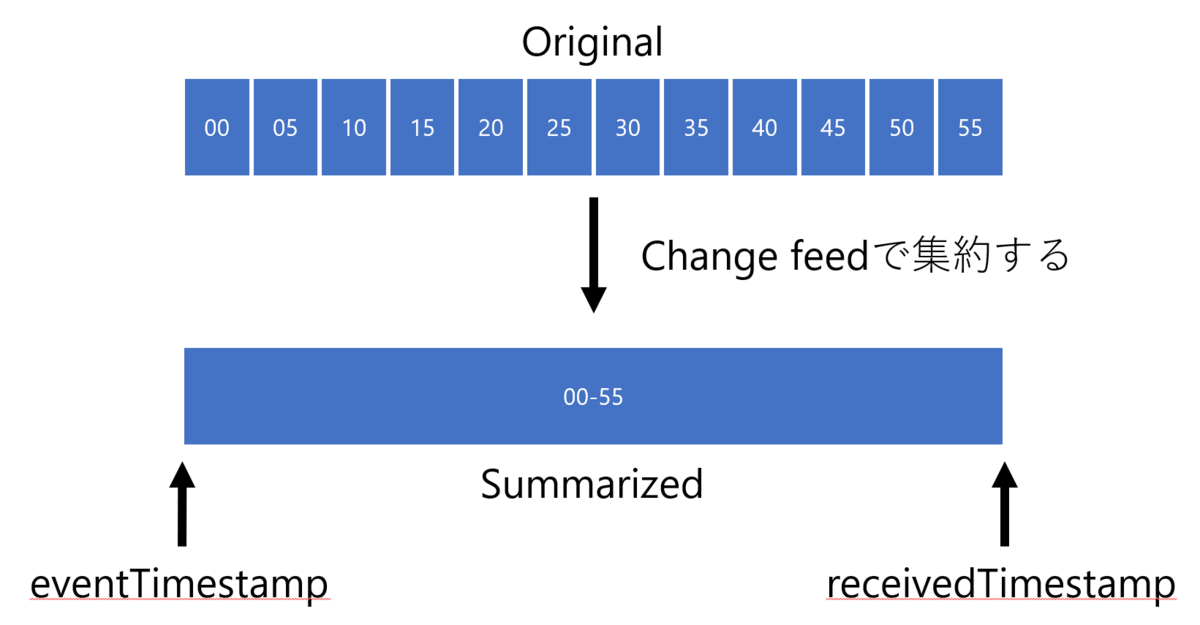
図にも書いていますが、オリジナルデータを集約するのはバッチプログラムでもいいですが、Azure Functions の Change feed トリガーを使用する方法もあります。
Data Binning パターンも NoSQL でよくやる方法ですね。
例によってサンプルコードは GitHub に公開されていますので、お試しください。


