こんにちは!オルターブースのいけだです!
早いものでもう6月ですね。
今年こそは妻の承認を貰って私の大好きな単車を買おうと息巻いてましたが、今年もまた見送りになりそうな雰囲気を感じている今日この頃です😭
さて、先日のMicrosoft Build で発表のあった通り、とうとうAzure Cosmos DB for NoSQLでベクトル検索が可能になりました!
これまでAzure Cosmos DBでは MongoDB vCoreでベクトル検索が可能ではありましたが、for NoSQL も対応となったことでよりRAG(Retrieval-Augmented Generation)構成などで使用するベクトルストアの選択肢がより広がり、より身近になったのでは無いかと感じます。
なお、こちらの機能はまだプレビュー段階ですのでご注意ください。
今回はこちらの機能を簡単に触ってみようと思います!
ベクトルインデックス作成ポリシー
まず、ドキュメントに記載のある使用できるベクトルインデックスの種類について読み解いてみましょう。
1. flat インデックス
- 概要
- flatインデックスは、他のインデックスプロパティと同じインデックスにベクトルをそのまま格納する。(圧縮などは行わない)
- 検索時に、全てのベクトルを比較するブルートフォース検索を行う。
- 精度は100%で、最も類似したベクトルを正確に見つけることができる。
- 利点
- 100%の精度を保証する。
- データセット内で最も類似したベクトルを確実に見つけることができる。
- 制限
- ベクトルの次元数は最大505まで。
- ベクトルの数が多いと、検索時間が長くなりやすく、リソース消費(RUコスト)が増加する。
2. quantizedFlat インデックス
- 概要
- quantizedFlatインデックスは、ベクトルをインデックスに格納する前に量子化(圧縮)する。
- 量子化により、わずかに精度を犠牲にするが、待機時間を短縮し、スループットを向上させる事ができる。
- ブルートフォース検索を行い、比較的正確に類似したベクトルを見つける。
- 利点
- flatインデックスに比べて、検索が速くなり、スループットが向上し、RUコストが低くなる。
- ベクトルの次元数は最大4096まで対応。
- 制限
- 精度がわずかに100%を下回る可能性がある。
- 効果を最大限に発揮するためには、少なくとも1,000個のベクトルが必要で、コンテナ内のベクトルが100,000個未満である必要がある。
3. diskANN インデックス
- 説明
- diskANNインデックスは、高速で効率的な近似ニアレストネイバー(ANN)検索を行うための特別なインデックス。
- Microsoft Researchによって開発されたDiskANNアルゴリズムを使用している。
- 精度はやや低下する可能性があるが、高いスループットと短い待機時間を提供する。
- 利点
- 高いスループット、最短の待機時間、低いRUコストを実現する。
- ベクトルの次元数は最大4096まで対応。
- 制限
- 精度はquantizedFlatやflatインデックスよりも低くなる可能性がある。
- 現在は限定的なプレビュー段階であり、利用には申請が必要。
OpenAIの埋め込みモデルを使用する場合は、少なくとも次元数1536以上が必要になります。
その場合、基本的にはquantizedFlatインデックス を使用し、より大規模な場合はdiskANNインデックスにすると良いのかなと思います。
試してみる
それではこちらのドキュメントを参考に試してみようと思います!
まず、CosmosDB for NoSQLのリソースを作成し、プレビュー機能の登録を行います。
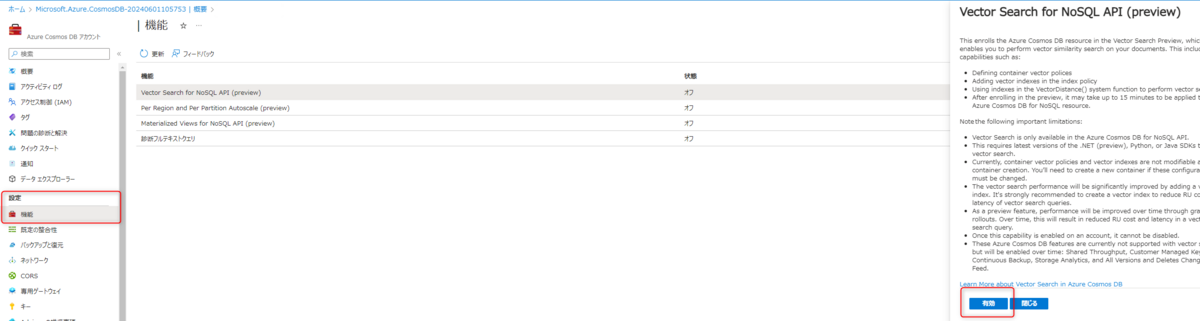
次に、データエクスプローラーから新規のデータベースとコンテナーを作成します。
その際にベクトルポリシーとインデックス作成ポリシーを定義します。
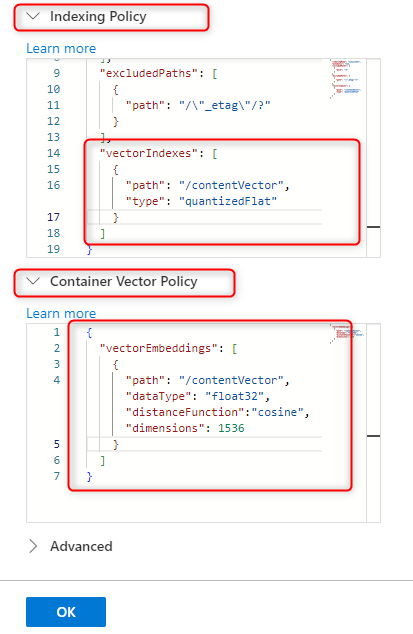
なお、今回はテスト用のデータとして200件ほどの映画レビューデータセットを使います。
件数は少ないのですが、text-embedding-ada-002を使って埋め込みをおこなうので、次元数は1536です。そのため、インデックスの種類はquantizedFlatインデックス を使おうと思います。
次に格納するデータを作成します。 この工程は以前書いた以下の記事と同様なので詳細は割愛します。
埋め込みの処理をおこなった以下形式のデータをCosmosDBに格納していきます。

from azure.cosmos import CosmosClient import os import json import openai from dotenv import load_dotenv import pandas as pd ... client = CosmosClient(doc_url, credential=doc_key) container = client.get_database_client("db").get_container_client("docs") for index, row in df.iterrows(): doc = { 'id': str(row['dialog_id']), 'review': row['review'], 'title': row['title'], 'year': row['year'], 'director': row['director'], 'director_description': row['director_description'], 'cast': row['cast'], 'cast_description': row['cast_description'], 'synopsis': row['synopsis'], 'contentVector': row['contentVector'], //埋め込みフィールド } container.create_item(body=doc)

ポータル画面からも格納されていることが確認できましたね。
それでは、検索クエリを発行してみます。
クエリは Vector Distance というシステム関数を使用するようです。
def get_embedding(text, model): text = text.replace("\n", " ") res = openai.embeddings.create(input = [text], model=model).data[0].embedding return res message = "家族で楽しめる映画" query_vector = get_embedding(message, model="text-embedding-ada-002") # 類似度TOP5 for item in container.query_items( query="SELECT TOP 5 c.title, c.review, VectorDistance(c.contentVector,@embedding) AS SimilarityScore FROM c ORDER BY VectorDistance(c.contentVector,@embedding)", parameters=[ {"name": "@embedding", "value": query_vector} ], enable_cross_partition_query=True): print(json.dumps(item, indent=True, ensure_ascii=False))
{
"title": "ALWAYS三丁目の夕日’64",
"review": "昭和の時代がすごく感じられる作品です。, ノスタルジックな映像がとても懐かしいです。, 家族の絆がよく描けていると思います。, ほのぼのとした昭和を、描いた映画です。, 戦後19年目にして見事な復興をした東京の下町を描いた懐かしい感じの映画",
"SimilarityScore": 0.8800420643488476
}
{
"title": "トイ・ストーリー",
"review": "おもちゃたちの頑張りやピュアなところに癒され、とても優しい気持ちになれる。, おもちゃの視点で描かれているのが面白い。, 童心に帰れる。二十年以上前の作品だとは思えない。, 続編として後に続いていくキャラの立ち方やストーリーの王道な感じ、歴史的な映画と言えるでしょう。, キャラクターがかわいくテンポが良いので大人も子供も楽しめる映画です!",
"SimilarityScore": 0.875090392025088
}
{
"title": "映画ドラえもんのび太と奇跡の島アニマルアドベンチャー",
"review": "見ていて心がほっこりして、家族みんなで気軽に楽しめると思います。, のび太のドジなところで一緒に笑ったり、家族で一緒に楽しめる作品です。, 何度も泣けて、笑えて、楽しめます。, 家族愛が感動的に描写されていて良いです。, のび太とのび太のパパの親子の絆が感じられた良作です。",
"SimilarityScore": 0.8709943891386392
}
{
"title": "マダガスカル3",
"review": "ダンスや音楽が楽しくて踊りながら観るともっと楽しくなる映画です。, 1,2を見ていなくても3のみで映画として成り立っているのでお勧め, ドリームワークスのCGアニメなので特に気になる!, 見ているうちに見入ってしまって笑いありでお子さんと一緒に見るのもおすすめ, 子供向け映画かと思いきや大人も楽しめる映画。",
"SimilarityScore": 0.8618412401791476
}
{
"title": "ファインディング・ニモ",
"review": "何度見ても飽きないい映画ですね, いわゆる「ディズニーアニメ」といった、家族で観ることができるアニメ作品です。, そこで仲間の魚たちが苦難を乗り越え、ニモを探しに旅に出る物語です。, 主役のキャラクターが明るく、やさしく癒されます, 色々な種類の魚があり、魚に合わせたキャラクター設定も面白くて、可愛いです。",
"SimilarityScore": 0.8590809047290431
}
簡単ではありますが、「家族で楽しめる」の表現に近しい作品達をちゃんと検索できましたね!
さいごに
AzureでRAG構成を考える際、AI Searchが真っ先に思い浮かぶかもしれません。 しかし、今回のCosmosDB for NoSQLのベクトル検索対応により、RAGを活用した機能の開発が一層身近なものになったように感じますね!
今回は以上となります。 拙い内容で恐縮ですが最後までご覧頂き有難うございました!🙏
サービス一覧 www.alterbooth.com cloudpointer.tech www.alterbooth.com


