こんにちは!オルターブースのいけだです!
今回は、Microsoft Fabricについて紹介します。 Microsoft Fabricは、先日のMicrosoft Build 2023で発表された、Microsoftの新しいSaasソリューションです。
※Microsoft Fabricは現在プレビュー段階です
Fabricではデータの収集、統合、分析、可視化を一括で行うことができます。 Fabricには以下のサービスが含まれており、データ技術者とビジネスサイドが共同作業する為のデータ統合環境です。
- データエンジニアリング
- データ統合
- データ ウェアハウス
- リアルタイム分析
- データ サイエンス
- ビジネスインテリジェンス
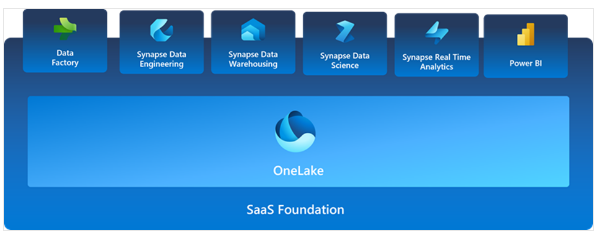
Fabricは、Saasとして提供されており、全てのデータがOneLakeに格納されます。 OneLakeにはプラットフォーム内のすべての分析エンジンからアクセスできます。
OneLakeとは?
OneLakeは、AzureDataLakeStorage 上に構築され、Delta、Parquet、CSV、JSON などの任意のファイル形式でデータを格納できます。
AzureStorageアカウントだけでなく、他のクラウド(AWS S3など)のデータを接続し、MicrosoftFabricでデータ活用をすることもできます。
そしてOneLakeの重要な機能の1つは、他のファイルまたはストレージの場所を指す OneLake 内に埋め込まれた参照であるショートカットを作成する機能です。 ショートカットを使用すると、コピーしなくても既存のクラウドデータをすばやくソース化でき、Fabricエクスペリエンスにより同じソースからデータを派生させ、常に同期させることができます。
ショートカットと聞くとOneDriveと同じように感じますが、 例えばAWSのS3に何かしらのファイルが保存されていたとしてもOneLakeでは参照する事ができるので、より透過的であると感じます。
Lakehouseとは?
作業を始める際には、Lakehouseを作成します。
Lakehouseとは、リレーショナル データ ウェアハウスの SQL ベースの分析機能と、データ レイクの柔軟性とスケーラビリティを組み合わせたものです。
利点としては以下が挙げられます。
- Lakehouseを使用すると、Spark エンジンと SQL エンジンを使用して大規模なデータを処理し、機械学習または予測モデリング分析をサポートできます。
- Lakehouseデータは、
スキーマ オン リード形式で編成されます。これは定義済みのスキーマを使用するのではなく、自分で必要に応じてスキーマを定義することを意味します。 - Lakehouseを使用すると、データの一貫性と整合性のための ACID (原子性、一貫性、分離性、持続性) トランザクションが Delta Lake 形式のテーブルを介してサポートされます。
- Lakehouseは、データ エンジニア、データ サイエンティスト、データ アナリストがデータにアクセスして使用するための一元化された場所です。
レイクハウスを作成した後、ローカル ファイル、データベース、API を含め、さまざまなソースから任意の一般的な形式のデータを読み込むことができます。
Microsoft Fabric の Data Factory パイプラインまたはデータフロー (Gen2) を使用してデータインジェストを自動化することもできます。
さらに、Azure Data Lake Store Gen2 やレイクハウス自体のストレージの外部にある Microsoft OneLake の場所など、外部ソース内のデータへのFabricショートカットを作成できます。
Lakehouse Explorer を使用すると、ファイル、フォルダー、ショートカット、テーブルを参照し、Fabric プラットフォーム内でその内容を表示できます。
Lakehouse にデータを取り込んだ後、ノートブックまたはデータフロー (Gen2) を使用してデータを探索および変換できます。
まず今回やってみた事
とにかく色々盛りだくさんのFabricですね!!
まず今回は、レイクハウスへのデータの取り込みからノートブックを使い、キーワード抽出、ネガポジ分析。そしてPowerBIでの可視化までを実施してみます!
手順としては以下の通りです。
- データレイクハウスにCosmosDBからデータを取り込む
- ノートブックでAzureTextAnalyticsを使い、キーワード抽出とネガポジ分析を実施する
- 整形したデータをBIを使い可視化をする
Microsoft Fabricを有効にして使用する
現在Microsot Fabricは無料試用版で開始する事ができます。
ライセンスはPowerBIライセンスが必要で、既存のライセンスを持っている場合は試用版をすぐに開始する事ができます。
レイクハウスにデータを取り込む
まず、新規にレイクハウスを作成します。
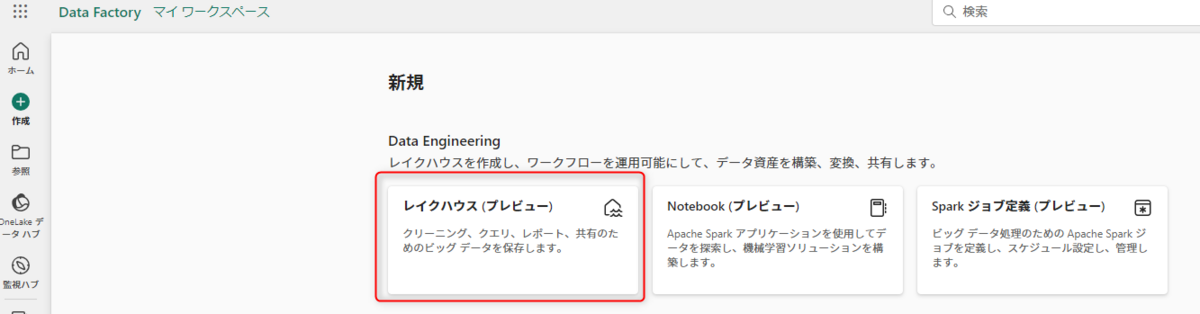
データパイプラインを作成します。

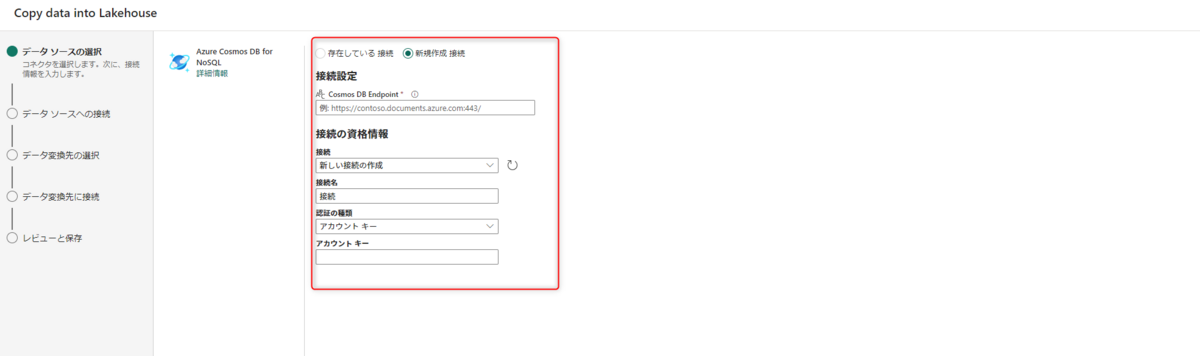
今回は、CosmosDBからデータを取り込みます。
CosmosDBコネクタを選択して、接続先エンドポイントとプライマリキーを入力します。
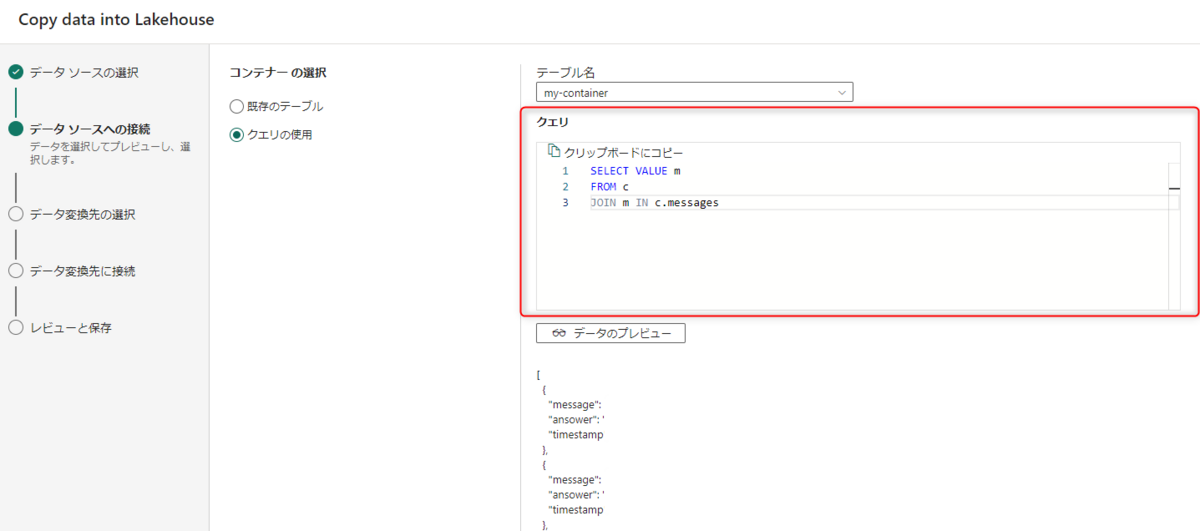
今回は、事前に格納しておいた、このような形式の仮データを用います。
建付けとしては、チャットボットアプリで格納しているデータという想定です。

取り込む際に、クエリをかけることができるので、メッセージ部分のみ抽出しておきます。
データパイプラインでの取り込みが成功すると、レイクハウスにテーブルが出来上がりました。


次にノートブックでAzureTextAnalyticsを使用して独自ラベルを付けていきます。
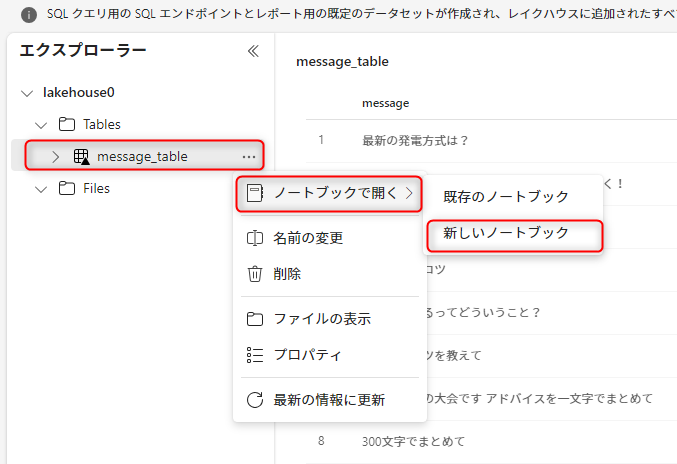
言語はPySparkを選択しました。
初めてPySparkを触りましたが、PythonのPandasと似た感じです。

以下はノートブックで行った手順になります。
#DF作成
df = spark.sql("SELECT * FROM lakehouse0.message_table")
display(df)
#必要なパッケージをinstall & import pip install azure-ai-textanalytics from pyspark.sql import SparkSession from pyspark.sql.functions import udf from pyspark.sql.types import ArrayType, StringType from azure.core.credentials import AzureKeyCredential from azure.ai.textanalytics import TextAnalyticsClient
# Text Analyticsの準備
credential = AzureKeyCredential("プライマリーキー")
endpoint="エンドポイント"
text_analytics_client = TextAnalyticsClient(endpoint, credential)
#キーワード抽出用
def extract_key_phrases(text):
response = text_analytics_client.extract_key_phrases([text], language="ja")
result = [doc for doc in response if not doc.is_error]
key_phrases = result[0].key_phrases if result else []
return key_phrases
# ネガポジ分析
def analyze_sentiment(text):
response = text_analytics_client.analyze_sentiment([text], language="ja")
result = [doc for doc in response if not doc.is_error]
sentiment = result[0].sentiment if result else "unknown"
return sentiment
# SparkSessionを生成 spark = SparkSession.builder.getOrCreate() # キーフレーズUDFを準備 extract_key_phrases_udf = udf(extract_key_phrases, ArrayType(StringType())) # ネガポジ分析UDFを準備 analyze_sentiment_udf = udf(analyze_sentiment, StringType())
#キーフレーズ抽出
df = df.withColumn("key_phrase", extract_key_phrases_udf(df["message"]))
# ネガポジ分析
df = df.withColumn("sentiment", analyze_sentiment_udf(df["message"]))
# 結果を表示 df100 = df.limit(10) display(df100)
ここまでの結果を表示してみます。
しっかり、キーフレーズとネガポジ分析の結果が反映されてます。

#ここまでのデータを保存する
df.write.mode("overwrite").parquet('Files/new_data')
print ("data saved!")
キーフレーズが現状では配列になっており、BIの際にやり辛いので加工します。
#key_phrase毎に新しい行を作成し、新しいDFを作成
from pyspark.sql import Row
new_rows = []
for row in df.collect():
# key_phrase配列の要素ごとに新しい行を作成し、リストに追加
for key_phrase in row.key_phrase:
new_rows.append((row.timestamp, key_phrase))
new_df = spark.createDataFrame(new_rows, ["timestamp","key_phrase"])
#新しくデータを保存する
new_df.write.mode("overwrite").parquet('Files/key_phrase_data')
print ("data saved!")

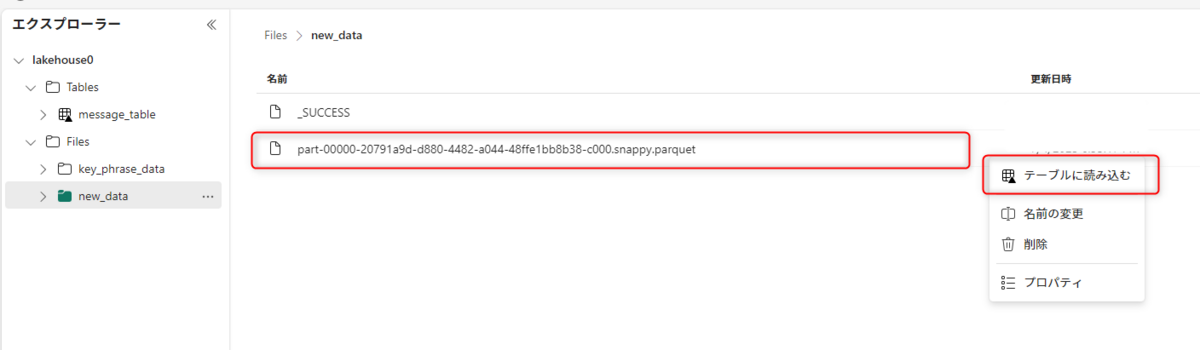
2つのデータファイルが作成されたので、レイクハウスへ移動します。
エクスプローラーからノートブックで作成したデータをテーブルに読み込みます。
上部のメニューから新しいPowerBIデータセットを選択します。
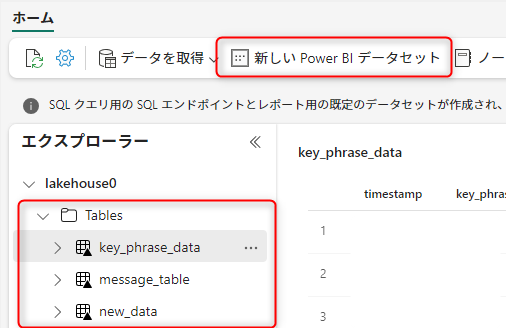
追加するデータセットを選択し、新しいレポートへと進みます。

BIの画面に移るので、ここではメッセージのネガポジ割合とメッセージに含まれるキーワードをグラフで表示してみました。
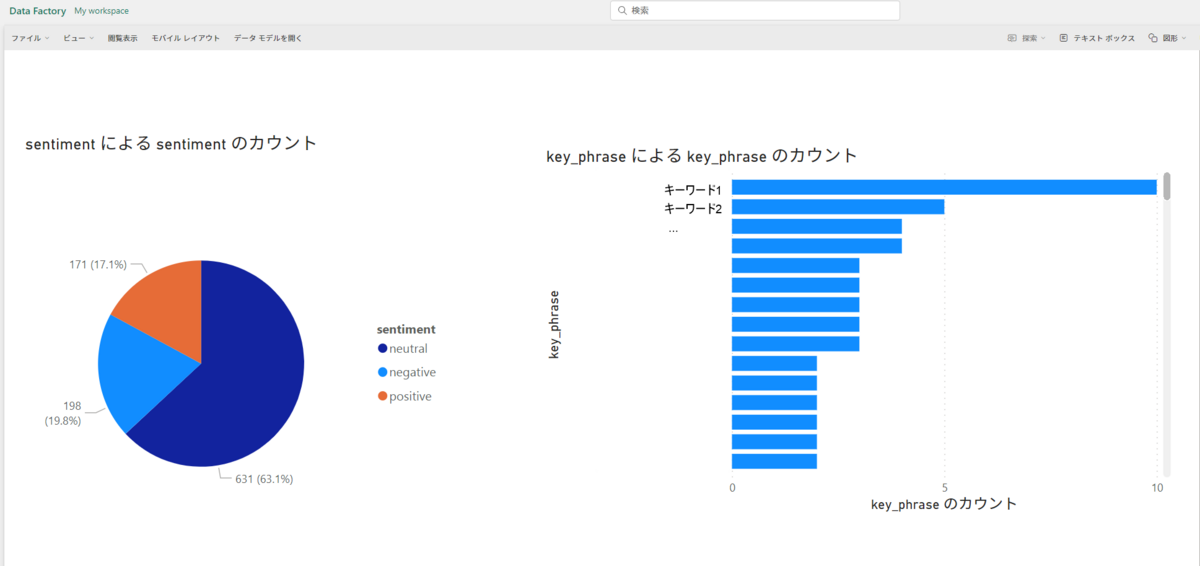
簡単ではありますが、一旦やりたかった事はできました!
最後に
今回は手探り状態でまずやってみましたが、Fabricには沢山の機能が搭載されているので今後も色々試してブログに投稿していこうと思います!
個人的にはデータパイプラインと、あらゆる場面でノートブックが開けるというのが面白いなと感じました。
現在はプレビュー段階ですが、近うちにCopilotも搭載されるというので益々期待ですね!
ここまでご覧頂き有難うございました!


